
机器学习——Python实践
- Numpy:
- python开源数值计算拓展,用来存储和处理大型矩阵,提供了许多高级的数值编程工具,如 矩阵数据类型、矢量处理、精密的运算库
- 利用Numpy数组来准备机器学习算法的数据
- python开源数值计算拓展,用来存储和处理大型矩阵,提供了许多高级的数值编程工具,如 矩阵数据类型、矢量处理、精密的运算库
- matplotlib:
- python中最著名的2D绘图库,适合交互式的进行制图;也可作为绘图空间,嵌入GUI应用程序中
- 创建图表,展示数据
- python中最著名的2D绘图库,适合交互式的进行制图;也可作为绘图空间,嵌入GUI应用程序中
- Pandas:
- 基于Numpy的工具,为了解决数据分析任务而创建的.~纳入了大量库和标准的数据模型,提供了操作大型数据集的工具,和快速便捷处理数据的函数和方法
- 导入、展示数据,以便挣钱对数据的理解和数据清洗、转换等工作
- 基于Numpy的工具,为了解决数据分析任务而创建的.~纳入了大量库和标准的数据模型,提供了操作大型数据集的工具,和快速便捷处理数据的函数和方法
预测模型所需的六个步骤:
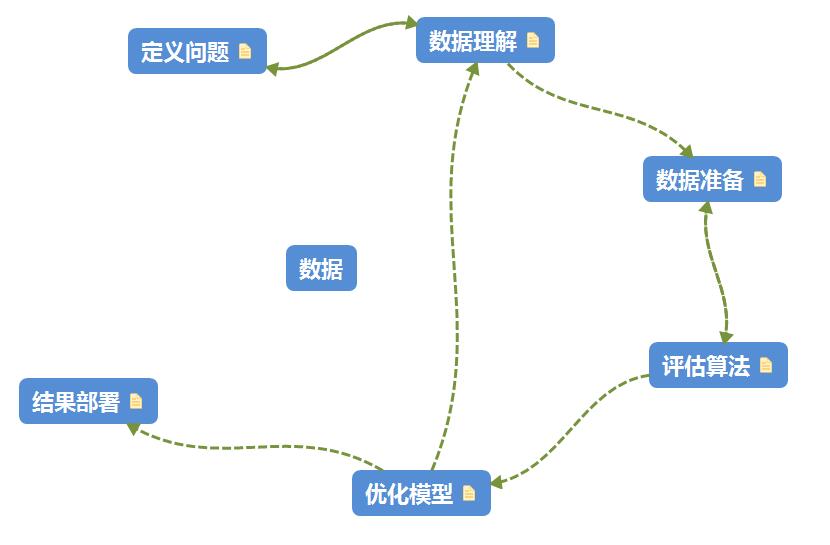
第一章:
鸢尾花(Iris Flower)
所有特征数据都是数字,不需要考虑如何导入和处理数据—>有的图表有标题等的,需要处理-
分类问题===>监督学习算法
多分类问题,可能需要一些特殊处理
所有特征的数值采用相同单位,不需要进行尺度转换
步骤:

1.导入数据集
1 | from pandas import read_csv |
2.概述数据
从下列角度审查数据:
数据的维度
查看数据的自身
统计描述所有的数据特征
数据分类的分布情况
1.数据的维度
了解数据集中有多少行数据,数据有几个属性
1 | print('数据的维度: 行 %s , 列 %s' % (dataset.shape)) |
2.参看数据本身
直观的看到数据的特征,数据的类型,以及大概的数据分布范围
1 | print(dataset.head(5)) |
3.统计描述数据
数据特征的统计描述信息包括数据的行数、中位值、最大值、最小值、均值、四分位值等统计数据信息
1 | print(dataset.describe()) |
4.数据分类分布
了解数据在不同分类的分布情况…==>每个分类数据量的绝对数值
1 | print(dataset.groupby('class').size()) |
▲ 如果数据分布不平衡,可能会影响到模型的准确性,…==>不平衡时,需要对数据进行调整,方法有:
- 扩大数据样本
- 通常容易被忽略的选择…但往往找到更大的数据集就有可能挖掘出更平衡的方面提高算法准确度
- 数据的重新抽样
- 过抽样(复制少数类样本)…数据少时考虑
- 欠抽样(删除多数类样本)…数据多时考虑
- 尝试生成人工样本
- 从少数类的实例中随机抽样特征属性,生成更多数据
- 异常检测和变化检测
- 尝试从不同观点思考,异常检测是对罕见事件的检测,将小类作为异常值类
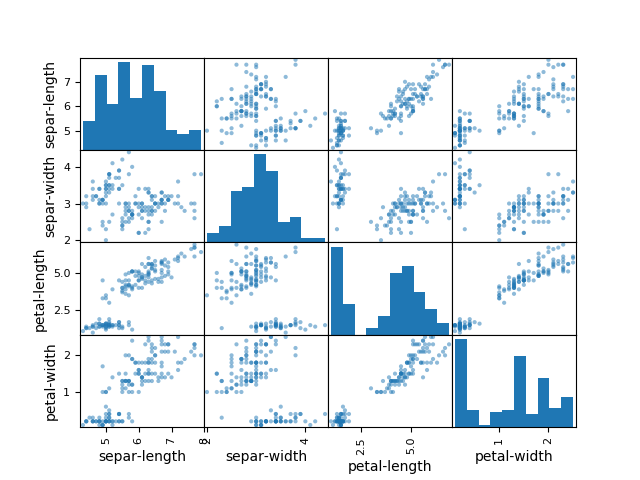
3.数据可视化
单变量图表: 理解每一个特征属性
多变量图表: 理解不同特征属性之间的关系
单变量图:
箱线图: 一种用作显示一组数据分散情况资料的统计图。因形状如箱子而得名。
主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比 较。箱线图的绘制方法是:先找出一组数据的最大值、最小值、中位数和两个四分位数;然后, 连接两个四分位数画出箱子;再将最大值和最小值与箱子相连接,中位数在箱子中间。
1 | #箱线图 , 因为每个特征属性都是数字 , 所以 用箱线图展示 属性与中位值的离散程度 |
多变量图:
1 | from pandas.plotting import scatter_matrix |
4.评估算法
- 分离出评估数据集
- 采用10折交叉验证来评估算法模型
- 生成6个不同的模型来预测新数据
- 选择最优模型
1.分离出评估数据集
❤️要想知道算法模型对真是数据的准确度,所以保留一部分数据来评估算法模型.
1 | from sklearn.model_selection import train_test_split |
2.评估模式
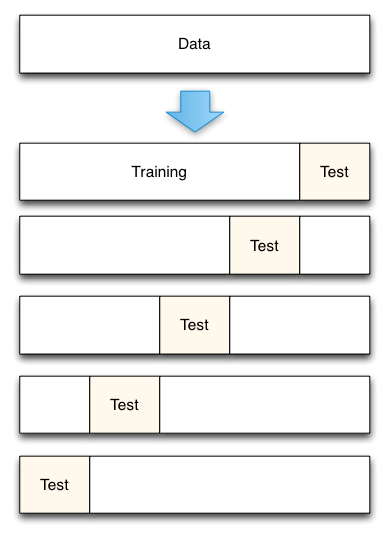
采用10折交叉验证来分离训练数据集 :
随机将数据分成10份,9份用来训练模型,1份用来评估算法
3.创建模型
线性
- 线性回归(LR)
- 线性判别分析(LDA)
非线性
- K近邻(KNN)
- 分类与回归树(CART)
- 贝叶斯分类器(NB)
- 支持向量机(SVM)
▲ 在每次对算法进行评估前都会重新设置随机数种子,以保证每次对算法的评估都是用相同的数据集
1 | from sklearn.linear_model import LogisticRegression,LinearRegression #LR |
4.选择最优模型
1 | >> |
为什么使用 10折交叉验证?
进行模型验证的一个重要目的是要选出一个最合适的模型,对于监督学习而言,我们希望模型对于未知数据的泛化能力强,所以就需要模型验证这一过程来体现不同的模型对于未知数据的表现效果。
训练准确度==>测试准确度
最先我们用训练准确度(用全部数据进行训练和测试)来衡量模型的表现,这种方法会导致模型过拟合(方差大);===>>为了解决这一问题,我们将所有数据分成训练集和测试集两部分,我们用训练集进行模型训练,得到的模型再用测试集来衡量模型的预测表现能力,这种度量方式叫测试准确度,这种方式可以有效避免过拟合。
测试准确度==>10折交叉验证
测试准确度的一个缺点是其样本准确度是一个高方差估计(high variance estimate), 所以该样本准确度会依赖不同的测试集,其表现效果不尽相同。
1 | for i in xrange(1,5): |
上面的测试准确率可以看出,不同的训练集、测试集分割的方法导致其准确率不同,而交叉验证的基本思想是:1.将数据集进行一系列分割,生成一组不同的训练测试集,2.然后分别训练模型并计算测试准确率,3.最后对结果进行平均处理。这样来有效降低测试准确率的差异。
K折交叉验证:
- 将数据集平均分割成K个等份子集
- 使用1份数据(子集)作为测试数据,其余(K-1)份作为训练数据
- 计算测试准确率
- 使用不同的测试集,重复2、3步骤
- 对测试准确率做平均,作为对未知数据预测准确率的估计 ==>
cross_val_score.mean()
不同的训练集、测试集分割的方法导致其准确率不同,而交叉验证的基本思想是:将数据集进行一系列分割,生成一组不同的训练测试集,然后分别训练模型并计算测试准确率,最后对结果进行平均处理。这样来有效降低测试准确率的差异。
来自周志华<<机器学习>>:
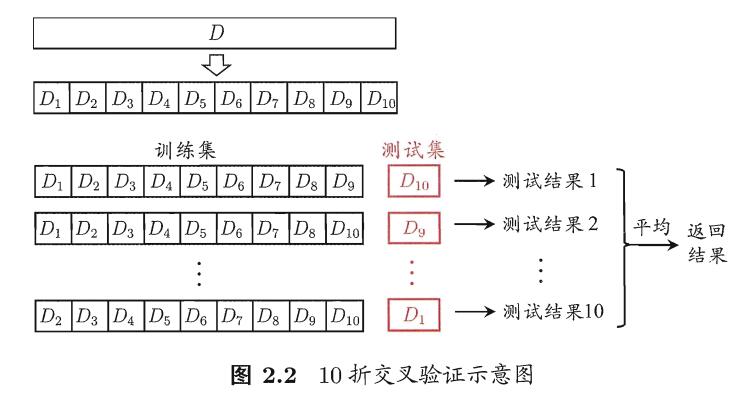
分割方法
1 | # 下面代码演示了K-fold交叉验证是如何进行数据分割的 |
1 | cv_result = cross_val_score(models[key],X_train,Y_train,cv = 10 , scoring = 'accuracy') |
5.实施预测
1 | #使用评估数据集评估算法 |
召回率(Recall Rate,也叫查全率)
是检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率;
精度(Precise)
-
TP: 预测为正,实际为正 (第一个是实际T或F,第二个是预测P或N)
-
FP: 预测为正,实际为负
-
TN:预测为负,实际为负
-
FN: 预测为负,实际为正
精确率、准确率:Accuracy=(TP+TN)/(TP+TN+FN+FP)
//精准率、查准率:P = TP/ (TP+FP)
召回率、查全率:R = TP/ (TP+FN)
F1-score: 2*TP/(2*TP + FP + FN)
◆. 精确度是“搜索结果有多大用处”,而召回是“结果如何完整”。
F1分数:
概述 : 统计学中用来衡量二分类模型精确度的一种指标。它同时兼顾了分类模型的准确率和召回率。F1分数可以看作是模型准确率和召回率的一种加权平均,它的最大值是1,最小值是0。
人们通常使用准确率和召回率这两个指标,来评价二分类模型的分析效果。
但是当这两个指标发生冲突时,我们很难在模型之间进行比较。比如,我们有如下两个模型A、B,A模型的召回率高于B模型,但是B模型的准确率高于A模型,A和B这两个模型的综合性能,哪一个更优呢?
| 准确率 | 召回率 | |
|---|---|---|
| A | 80% | 90% |
| B | 90% | 80% |
为了解决这个问题,人们提出了 分数。的物理意义就是将准确率和召回率这两个分值合并为一个分值,在合并的过程中,召回率的权重是准确率的 倍。分数认为召回率和准确率同等重要, 分数认为召回率的重要程度是准确率的2倍,而分数认为召回率的重要程度是准确率的一半。
▲ 如何计算Precise、Recall、F1-score见博客https://blog.csdn.net/akadiao/article/details/78788864
Confusion_martrix(混淆矩阵)
混淆矩阵: 一种特定的矩阵用来呈现算法性能的可视化效果,通常是监督学习(非监督学习,通常用匹配矩阵:matching matrix)
其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
Example样例说明:
假设有一个用来对猫(cats)、狗(dogs)、兔子(rabbits)进行分类的系统,混淆矩阵就是为了进一步分析性能而对该算法测试结果做出的总结。假设总共有 27 只动物:8只猫, 6条狗, 13只兔子。结果的混淆矩阵如下图:
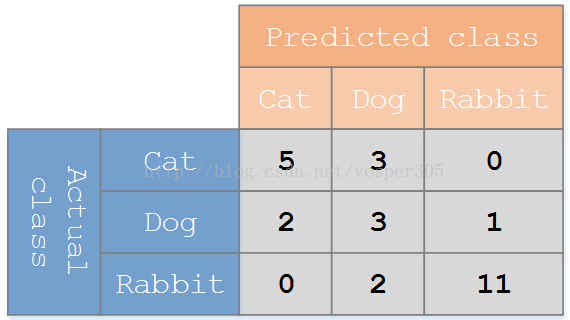
在这个混淆矩阵中,实际有 8只猫,但是系统将其中3只预测成了狗;对于 6条狗,其中有 1条被预测成了兔子,2条被预测成了猫。从混淆矩阵中我们可以看出系统对于区分猫和狗存在一些问题,但是区分兔子和其他动物的效果还是不错的。所有正确的预测结果都在对角线上,所以从混淆矩阵中可以很方便直观的看出哪里有错误,因为他们呈现在对角线外面。****
Author: Mrli
Link: https://nymrli.top/2018/11/23/机器学习——Python实践-笔记/
Copyright: All articles in this blog are licensed under CC BY-NC-SA 3.0 unless stating additionally.