
SQL练习
鉴于同学被字节狂问SQL题,因此也激发了我的危机感。 作为非科班的, 写SQL还是比较慌的, 因此做下专题训练。
理论知识:
SQL语句执行顺序
1.sql执行顺序
1 | (1) from |
1 | (8) SELECT (9)DISTINCT<select_list> |
用group by需要注意的:
- 在select指定的字段
- 要么就是包含在Group By语句的后面,为作为分组的依据的字段;
- 要么就要被包含在聚合函数中, e…g:
sum, avg, count。
SQL查询语句中的 limit 与 offset 的区别:
limit y分句表示: 读取 y 条数据limit x, y分句表示: 跳过 x 条数据,读取 y 条数据limit y offset x分句表示: 跳过 x 条数据,读取 y 条数据
分页操作
语法:limit开始索引,每页查询的记录数
注:索引从0开始
公式:开始索引=(当前页码-1)*每页查询的记录数即 index = (nowPageNum - 1) * pageSize
1 | SELECT * FROM table |
引号区别
在标准 SQL 中,字符串使用的是单引号。
如果字符串本身也包括单引号,则使用两个单引号(注意,不是双引号,字符串中的双引号不需要另外转义)。
但在其它的数据库中可能存在对 SQL 的扩展,比如在 MySQL 中允许使用单引号和双引号两种。
MySQL 参考手册:
字符串指用单引号
'或双引号"引起来的字符序列。例如:
‘a string’
“another string”
如果SQL服务器模式启用了NSI_QUOTES,可以只用单引号引用字符串。用双引号引用的字符串被解释为一个识别符。
1 | 使用双字符: |
反引号(`)
1 | 保留字不能用于表名,比如desc,此时需要加入反引号来区别,但使用表名时可忽略反引号。 |
字符串数据是用单引号包在外面的,而+号只是用来连接这些字符串的. 数据库里的字段是整型的时候不要加单引号,是字符串的时候要加,其它类型根据实际情况来,双引号就是用来拼接字符串的,单引号是sql文的固有写法,因为你要动态的来拼接,涉及到变量,所以要用“+”来组合各个字符串片段。最终结果无非就是得出能在数据库查询分析器中执行的sql文。
1 | String sql = "insert into student values ( " + student.getId() + " ,' " |
因为id和age是int型的所以不用加单引号,你的Username在数据库中定义的是一个varchar型的,而对字符型进行条件查询的时候是要加 ’ '号的:select count(*) from student where username= 'aaa '
因此在后台写查询字符串的时候就必须这样写: string sql = "select count(*) from student where username= ' "+userName+ " ' ",这样映射成的查询语句就是: select count(*) from student where student= 'aaa ' 了.
题目
1 查找最晚入职员工的所有信息(入门题)
1 | select * from employees order by hire_date limit 1; |
2查找入职员工时间排名倒数第三的员工所有信息
1 | select * from employees |
SQL查询语句中的 limit 与 offset 的区别:
limit y分句表示: 读取 y 条数据limit x, y分句表示: 跳过 x 条数据,读取 y 条数据limit y offset x分句表示: 跳过 x 条数据,读取 y 条数据
3 查找各个部门当前领导当前薪水详情以及其对应部门编号dept_no
1 | select s.*, d.dept_no |
4 查找所有已经分配部门的员工的last_name和first_name
1 | select e.last_name, e.first_name, d.dept_no |
5查找所有员工的last_name和first_name以及对应部门编号dept_no
暂时没有分配具体部门的员工==> employees有信息, 而dept_emp表中可能还没有信息;两表联合查询时以employees为准, 匹配不到dept_emp的数据用null填充—>所以用外部联结的左联结
1 | select e.last_name, e.first_name, d.dept_no |
join
内联结(Inner join)
联接仅返回两个联接表中都具有匹配项的行。例如,您可以将employees和departments表联接在一起,以创建一个显示每个雇员的部门名称的结果集。在内部联接中,没有部门信息的雇员不包括在结果集中,没有雇员的部门也不会包括在结果集中。
外联结(Outer join)
外联接是内部联接的扩展。 即使外联接在联接表中没有相关行,外联接也会返回这些行。 外联接共有三种类型:左联接(left join),右联接(right join)和完全联接(full join)。
left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等(有匹配项)的记录 ,否则用NULL
right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
inner join(等值连接) 只返回两个表中联结字段相等的行

总结:
- inner join是两集合取交集
- FULL [OUTER] JOIN: 两集合取并集
- left [outer] join: 产生表A的完全集, B中有匹配则有值, 没匹配则为null
- left join是以A表的记录为基础的,A可以看成左表,B可以看成右表,left join是以左表为准的.换句话说,左表(A)的记录将会全部表示出来,而右表(B)只会显示符合搜索条件的记录(例子中为: A.aID = B.bID).
B表记录不足的地方均为NULL填充.
- left join是以A表的记录为基础的,A可以看成左表,B可以看成右表,left join是以左表为准的.换句话说,左表(A)的记录将会全部表示出来,而右表(B)只会显示符合搜索条件的记录(例子中为: A.aID = B.bID).
Q: 最上层的两张图分别是全A和全B,那么left join和right join的作用是什么呢?
A: 联表查询, 拓展字段
6 查找所有员工入职时候的薪水情况
两表并列查找,题目重点在于: 有多条薪水信息中找出入职时候的薪水情况
1 | select e.emp_no, s.salary |
联表查询
1 | select e.emp_no,s.salary |
7查找薪水涨幅超过15次的员工号emp_no以及其对应的涨幅次数t
- 将select出来的数据重命名
- having用法
1 | select s.emp_no, count(s.emp_no) as t |
Question:
Q: select count(s.emp_no) as t的执行顺序在having t > 15之前吗?
A: No是聚合函数count优先于having
SQL 别名: AS
- SQL 别名用于为 表 或 表中的列 提供临时名称。
- SQL 别名通常用于使 表名 或 列名 更具可读性。
- SQL 一个别名只存在于查询期间。
别名使用 AS 关键字赋予。
什么情况下需要给表起别名?
1.表名比较长
2.当需要在多个表中进行查询并把查询内容同时输出的时候
3.当需要进行表连接的时候(其实和2一个意思,一般情况下多个表进行连接主要目的就是为了从多个表中查询所需要的内容)
having
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
聚合函数
聚合函数对一组值执行计算并返回单一的值
聚合函数有什么特点?
- 除了 COUNT 以外,聚合函数忽略空值。
- 聚合函数经常与 SELECT 语句的 GROUP BY 子句一同使用。
- 所有聚合函数都具有确定性。任何时候用一组给定的输入值调用它们时,都返回相同的值。
- 标量函数:只能对单个的数字或值进行计算。主要包括字符函数、日期/时间函数、数值函数和转换函数这四类。
8 找出所有员工当前具体的薪水salary情况
1 | select distinct salary |
说明:
对于distinct与group by的使用:
1.当对系统的性能高并且数据量大时使用group by
2.当对系统的性能不高时或者使用数据量少时两者借口
3.尽量使用group by
9获取所有部门当前manager的当前薪水情况
1 | -- 用where连接并列查询的两表 |
10 获取所有非manager的员工emp_no
把在dept_manager中的都筛选掉, 之前join的练习: A - A∩B
1 | -- LEFT JOIN左连接 + IS NULL |
使用见: #join
- 只有left join的效果
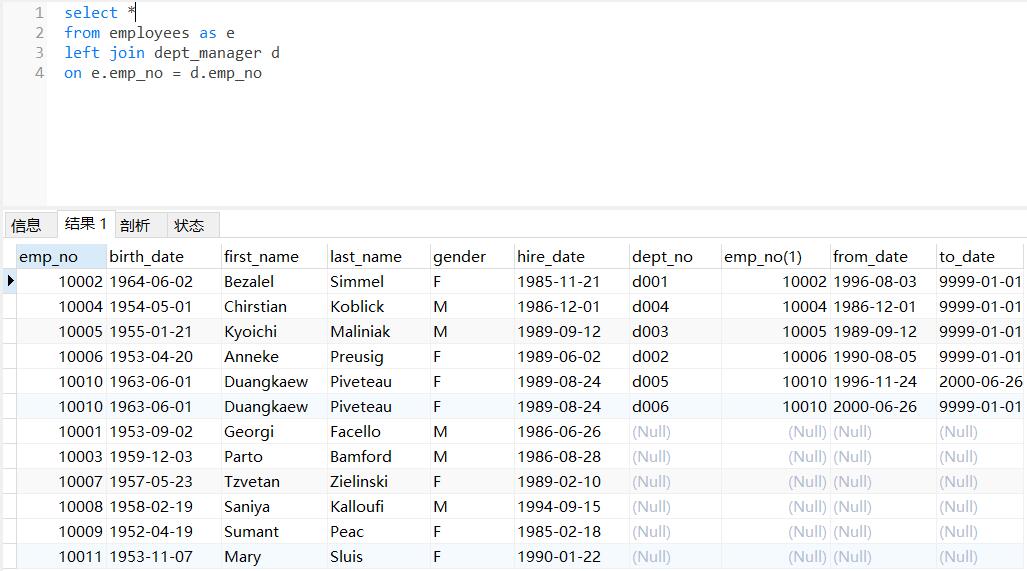
- 加上is null的效果 ==> 找出B表中emp_no不匹配的(他们填充的数据都是null)
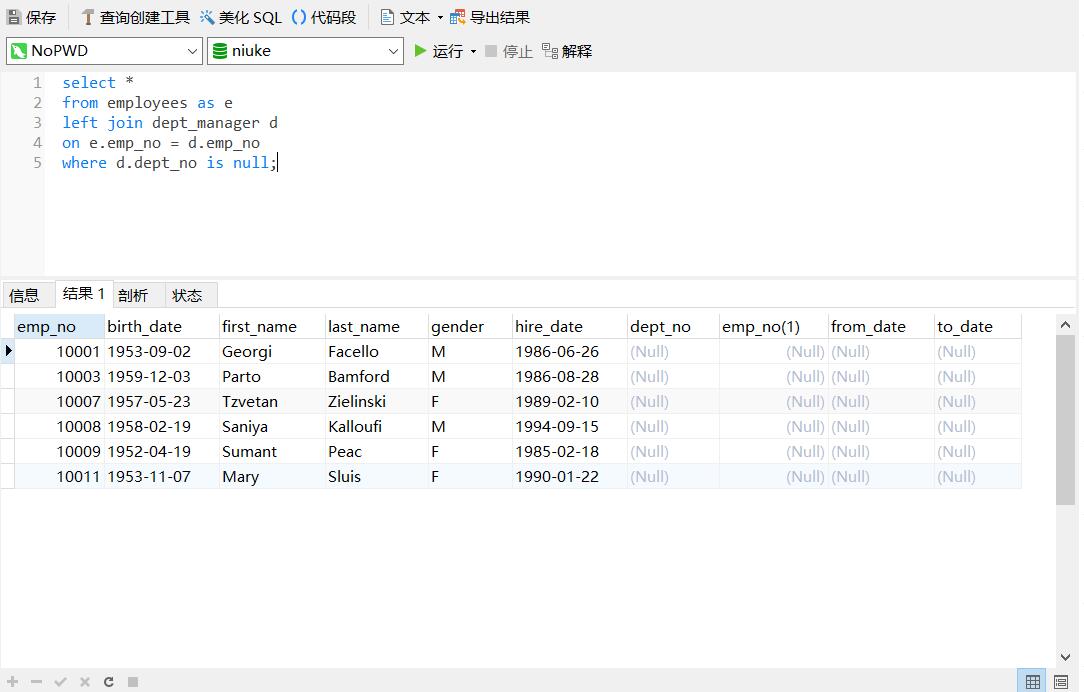
11 获取所有员工当前的manager
1 | -- my |
12 获取所有部门中当前员工薪水最高的相关信息
1 | select de.dept_no, de.emp_no, max(s.salary) |
使用GROUP BY子句时,SELECT子句中只能有聚合键、聚合函数、常数。
13 从titls表获取按照title进行分组
1 | select title, count(title) as t |
14 从titles表获取按照title进行分组,注意对于重复的emp_no进行忽略
忽略重复的emp_no, 上题的count(title) 其实可以写成count(emp_no) , 即有一条包含title的条目就++,而emp_no是其主键, 因此可以用emp_no的数目来代替title的数目。因此这题要求的不重复emp_no直接加个distinct即可
1 | select title, count(distinct emp_no) as t |
15 查找employees表所有emp_no为奇数
1 | select emp_no, birth_date, first_name, last_name, gender, hire_date |
16 统计出当前各个title类型对应的员工当前薪水对应的平均工资
通过t.title来进行分组
1 | select t.title, avg(s.salary) |
注意:AVG(*)是自动命名为avg的,所以不用重命名
17 获取当前薪水第二多的员工的emp_no以及其对应的薪水
考验limit用法
1 | select emp_no, salary |
18 查找当前薪水排名第二多的员工编号emp_no
1 | -- 用MAX函数,先查出最大salary,再利用<得到不含最大salary的子表,在子表上再求最大值 |
19查找所有员工的last_name和first_name以及对应的dept_name
- 列出
employees表里所有员工last_name, first_name,- 根据
employees中emp_no对应dept_emp中的dept_no,没有分配的员工找不到对应–>采用LEFT JOIN- 再根据dept_no对应
departments表中的dept_name,没有分配的员工找不到对应–>采用LEFT JOIN
1 | select e.last_name, e.first_name, dm.dept_name |
20查找员工编号emp_now为10001其自入职以来的薪水salary涨幅值growth
最大值-最小值
1 | -- 题解, sum的结果默认为growth |
21 查找所有员工自入职以来的薪水涨幅情况
这题比较有难度
1 | select la.emp_no, (now.salary - la.salary) as growth |
22统计各个部门的工资记录数
1 | -- my |
23对所有员工的当前薪水按照salary进行按照1-N的排名
SQL窗口函数(OLAP函数)中用于排序的专用窗口函数用法: RANK函数的使用 ->mysql不支持
1 | select emp_no, salary, dense_rank() over (order by salary desc) as rank |
下面介绍三种用于进行排序的专用窗口函数:
1、RANK()
在计算排序时,若存在相同位次,会跳过之后的位次。
例如,有3条排在第1位时,排序为:1,1,1,4······
2、DENSE_RANK()
这就是题目中所用到的函数,在计算排序时,若存在相同位次,不会跳过之后的位次。
例如,有3条排在第1位时,排序为:1,1,1,2······
3、ROW_NUMBER()
这个函数赋予唯一的连续位次。
例如,有3条排在第1位时,排序为:1,2,3,4······
窗口函数用法:
1 | <开窗函数> over ([partition by <列清单>] order by <排序用列清单>) |
开窗函数大体可以分为以下两种:
1.能够作为开窗函数的聚合函数(sum,avg,count,max,min)
2.rank,dense_rank。row_number等专用开窗函数。
1.4 开窗函数和聚合函数的区别
(1)SQL 标准允许将所有聚合函数用作开窗函数,用OVER 关键字区分开窗函数和聚合函数。
(2)聚合函数每组只返回一个值,开窗函数每组可返回多个值。
24 获取所有非manager员工当前的薪水情况
1 | -- 方法1:多表联查+NOT IN |
25 获取员工其当前的薪水比其manager当前薪水还高的相
1 | select de.emp_no, dm.emp_no as manager_no, s1.salary as emp_salary, s2.salary as manager_salary |
26 汇总各个部门当前员工的title类型的分配数目
1 | use niuke; |
对于group by多个关键字的使用, 见B站视频
- group by和distinct可以实现相同效果, 在redshift中group by快于distinct
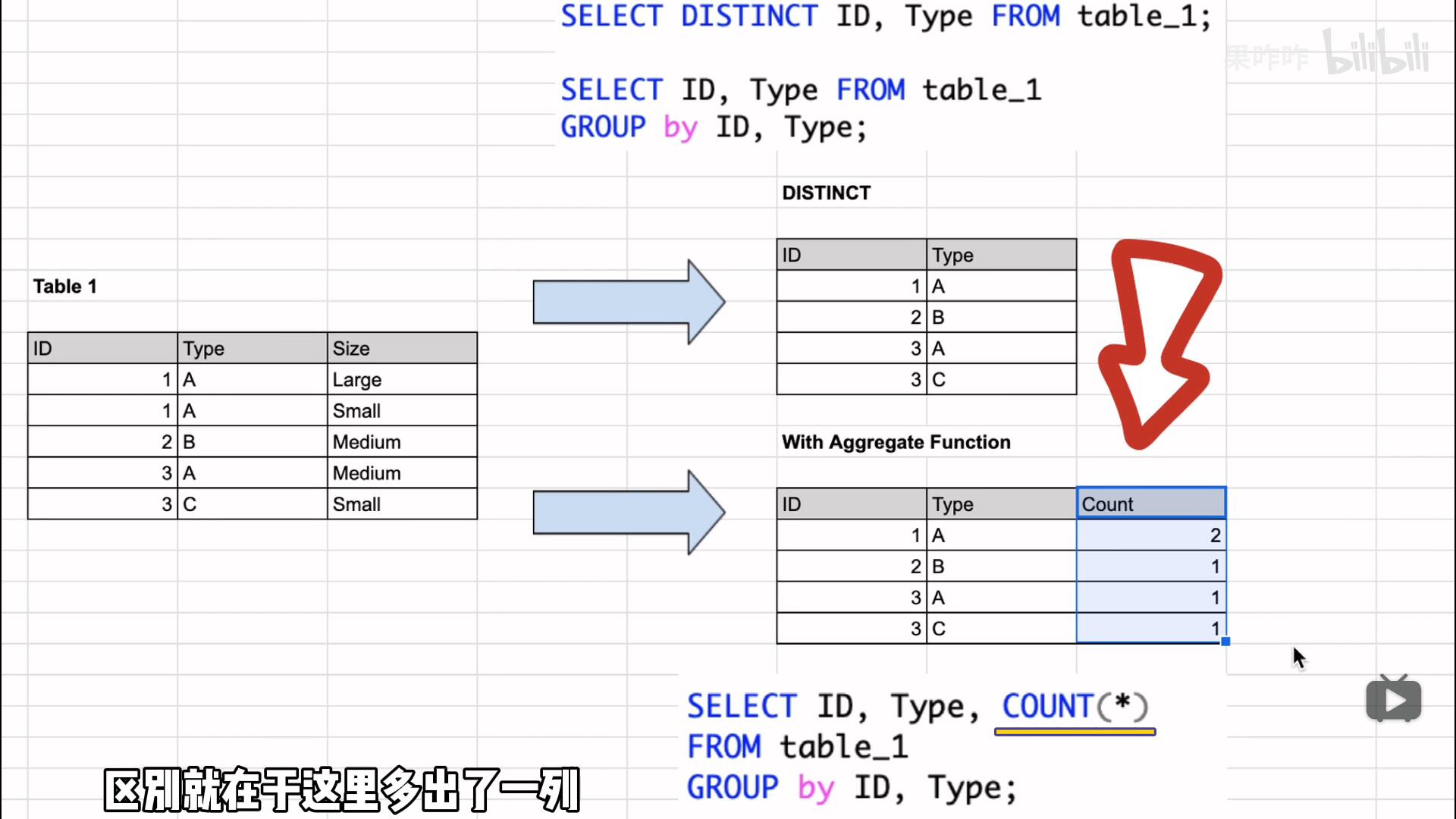
27 给出每个员工每年薪水涨幅超过5000的员工编号emp_no
1 | -- 两个salary子查询相减: 表内根据某一列进行差值比较, 就需要分别获得两行数据, 因此可以获得两次表, on找到对应数据 |
注意: 这边只能是(inner) JOIN, 如果LEFT JOIN, RIGHT JOIN会报错; 原数据7条, join以后变成49条(把s2的每一条都对应给了s1的每一条, 7*7)==>和SELECT * FROM salaries AS s1, salaries AS s2;效果一样,但left join、right join效果不一样
1 | -- 其他题 |
28 查找描述信息中包括robot的电影对应的分类名称以及电影数目
这题题意其实是有一点绕的: 查找描述信息中包含robot的电影对应的分类名称以及电影数目,注意需要该分类包含电影总数量>=5部
包含robot的数据, 通过like选出: select * from film where film.description like '%robot%';
记录:
- category: 16条
- film: 10条
- film_category: 10条
1 | select * from film f,category c,film_category fc -- 1600条数据 |
▲注: 这题无论怎么写在本地的MYSQL上都跑不出来, 但是OJ上能过. 具体报错为: In aggregated query without GROUP BY, expression #1 of SELECT list contains nonaggregated column 'niuke.c.name'; this is incompatible with sql_mode=only_full_group_by, 这个是由于sql_mode设置不当引起的,修改下sql_mode即可. 做法为: https://cloud.tencent.com/developer/article/1404739
29 使用join查询方式找出没有分类的电影id以及名称
1 | select f.film_id as '电影id', f.title as '名称' |
30 使用子查询的方式找出属于Action分类的所有电影对应的title,description
要求子查询, 就需要先根据类别为Action将子表给筛选出来
1 | -- 联子表, 用inner join一样的 |
inner join 和 where比较(实际上是cross join笛卡尔积)
1 | A: select a.x, b.x |
一般不建议使用方法A和B,因为如果有WHERE子句的话,往往会先生成两个表行数乘积的行的数据表然后才根据WHERE条件从中选择。因此,如果两个需要求交际的表太大,将会非常非常慢,不建议使用。
连接查询与子查询
初步实践证明:连接查询的性能优于子查询,所以能用连接查询的地方尽量少用子查询
连接查询
连接查询是将两个或多个的表按某个条件连接起来,从中选取需要的数据,连接查询是同时查询两个或两个以上的表的使用的。当不同的表中存在相同意义的字段时,可以通过该字段来连接这几个表。
32 将employees表的所有员工的last_name和first_name拼接起来作为Name,中间以一个空格区分
1 | -- sqlite中无concat函数 |
练习CRUD
33 创建一个actor表,包含如下列信息
1 | -- 发现图中有的含义列不需要用comment表示出 |
34 批量插入数据
1 | insert into `actor`values |
35 批量插入数据,如果数据已经存在,请忽略,不使用replace操作
1 | -- sqlite |
36 创建一个actor_name表,将actor表中的所有first_name以及last_name导入改表
1 | CREATE TABLE IF NOT EXISTS `actor_name`( |
37 对first_name创建唯一索引uniq_idx_firstname,对last_name创建普通索引idx_lastname
1 | -- sqlite在已有表上创建索引方式 |
38 针对actor表创建视图actor_name_view
1 | CREATE VIEW actor_name_view AS |
39 针对上面的salaries表emp_no字段创建索引idx_emp_no,查询emp_no为10005,
针对salaries表emp_no字段创建了索引idx_emp_no。请强制使用索引查询emp_no为10005
2
3
4
5
6
> SELECT|DELETE|UPDATE column1, column2...
> INDEXED BY (index_name)
> table_name
> WHERE (CONDITION);
>
它可以与 DELETE、UPDATE 或 SELECT 语句一起使用。
“INDEXED BY index-name” 子句规定必须用命名的索引来查找前面表中值,如果索引名 index-name 不存在或不能用于查询,SQLite 语句的查询失败。
1 | SELECT * FROM salaries INDEXED BY idx_emp_no WHERE emp_no = 10005 |
40 在last_update后面新增加一列名字为create_date
1 | -- 向表中添加列 |
41 构造一个触发器audit_log,在向employees表中插入一条数据的时候,触发插入相关的数据到audit中
1 | -- 在MySQL中,创建触发器语法如下: |
- trigger_name:标识触发器名称,用户自行指定;
- trigger_time:标识触发时机,取值为 BEFORE 或 AFTER;
- trigger_event:标识触发事件,取值为 INSERT、UPDATE 或 DELETE;
- tbl_name:标识建立触发器的表名,即在哪张表上建立触发器;
- trigger_stmt:触发器程序体,可以是一句SQL语句,或者用 BEGIN 和 END 包含的多条语句,每条语句结束要分号结尾。
1 | create trigger audit_log |
【NEW 与 OLD 详解】
MySQL 中定义了 NEW 和 OLD,用来表示触发器的所在表中,触发了触发器的那一行数据。
具体地:
- 在 INSERT 型触发器中,NEW 用来表示将要(BEFORE)或已经(AFTER)插入的新数据;
- 在 UPDATE 型触发器中,OLD 用来表示将要或已经被修改的原数据,NEW 用来表示将要或已经修改为的新数据;
- 在 DELETE 型触发器中,OLD 用来表示将要或已经被删除的原数据;
使用方法: NEW.columnName (columnName 为相应数据表某一列名)
42 删除emp_no重复的记录,只保留最小的id对应的记录。
1 | delete from titles_test where id not in ( |
43 将所有to_date为9999-01-01的全部更新为NULL,且 from_date更新为2001-01-01
1 | update titles_test set to_date = null, from_date = '2001-01-01' where to_date ='9999-01-01'; |
44 将id=5以及emp_no=10001的行数据替换成id=5以及emp_no=10005,其他数据保持不变,使用replace实现。
1 | -- 考察replace函数: 其中包含三个参数,第一个参数为该字段的名称,第二参数为该字段的需要被修改值,第三个参数为该字段修改后的值 |
45 将titles_test表名修改为titles_2017
1 | -- 因为在 MySQL里面修改表名和表里的字段都是用的 ALTER TABLE + table_name + 后面的修改部分 |
结合[40 在last_update后面新增加一列名字为create_date](#40 在last_update后面新增加一列名字为create_date)一起看
- ALTER TABLE 表名 ADD 列名/索引/主键/外键等;
- ALTER TABLE 表名 DROP 列名/索引/主键/外键等;
- ALTER TABLE 表名 ALTER 仅用来改变某列的默认值;
- ALTER TABLE 表名 RENAME 列名/索引名 TO 新的列名/新索引名;
- ALTER TABLE 表名 RENAME TO/AS 新表名;
- ALTER TABLE 表名 MODIFY 列的定义但不改变列名;
- ALTER TABLE 表名 CHANGE 列名和定义都可以改变。
46 在audit表上创建外键约束,其emp_no对应employees_test表的主键id
1 | DROP TABLE audit; |
48 将所有获取奖金的员工当前的薪水增加10%
1 | update salaries set salary = 1.1*salary |
50 将employees表中的所有员工的last_name和first_name通过(’)连接起来。
1 | select (last_name || "'" || first_name ) as name from employees; |
51 查找字符串’10,A,B’
把串 “10,A,B” 中的 逗号用空串替代, 变成了 “10AB”, 然后原来串的长度 - 替换之后的串的长度 就是 被替换的 逗号的个数
1 | select ( length('10,A,B') - length(replace('10,A,B', ',', '')) ) as cnt; |
52 获取Employees中的first_name,查询按照first_name最后两个字母,按照升序进行排列
用mysql的话有函数
right函数。就是取右边第几位的意思,同样还有一个 left 函数。select * from salaries order by right(emp_no,2)但是本题数据库是SQlite 只能用substr(emp_no,-2)
1 | select e.first_name |
53 按照dept_no进行汇总,属于同一个部门的emp_no按照逗号进行连接,结果给出dept_no以及连接出的结果employees
聚合函数
group_concat(X,Y),其中X是要连接的字段,Y是连接时用的符号,默认为逗号,可省略。此函数必须与GROUP BY配合使用。此题以dept_no作为分组,将每个分组中不同的emp_no用逗号连接起来(即可省略Y)。
1 | select dept_no, group_concat(emp_no) as employees |
54 查找排除当前最大、最小salary之后的员工的平均工资avg_salary
1 | select avg(s.salary) as avg_salary |
55 分页查询employees表,每5行一页,返回第2页的数据
limit offset, size
size是每页几条数据pageCnt,分页时offset输出页数(pageNum-1)*pageCnt
1 | select * |
56 获取所有员工的emp_no
57 使用含有关键字exists查找未分配具体部门的员工的所有信息。
59 获取有奖金的员工相关信息。
60 统计salary的累计和running_total
66 牛客每个人最近的登录日期(一)
1 | select max(date) |
67 牛客每个人最近的登录日期(二)
1 | select user.name,client.name,max(login.date) |
用group by需要注意的:
- 在select指定的字段
- 要么就要包含在Group By语句的后面,作为分组的依据;
- 要么就要被包含在聚合函数中。
Author: Mrli
Link: https://nymrli.top/2020/09/04/SQL练习/
Copyright: All articles in this blog are licensed under CC BY-NC-SA 3.0 unless stating additionally.