
ZJU要求
课程内容
- 云计算基本概念和Docker容器原理(4课时)
- Kubernetes核心原理与关键组件 (8课时)
- 微服务技术原理与治理 (4课时)
- 容器监控与分析 (4课时)
- 云原生边缘计算技术(4课时)
- IBM讲座-混合云架构(4课时)
- 云原生应用实践与案例分析(4课时)
考核方式
平时(20%)+ 课程设计(80%,含报告)
课程设计(三选一)
-
云原生技术研究报告或综述
围绕云原生关键技术点,如容器安全、多集群管理、云边协同和边缘智能等,综述当前技术现状并进行必要的分析
-
源代码分析报告
分析Kubernetes或者KubeEdge等云原生项目相关源代码,撰写代码分析报告(行级代码标注+工作流分析),不少于10页,原创。
-
开源贡献
修改Kubernetes/KubeEdge/Docker提交PR,根据代码行数折算(100行源代码或者5个commit)
未能通过社区审核,通过测试验证的代码可以作为参考评分
云原生
Docker技术原理与实践
Docker是Docker公司开源的一个基于轻量级虚拟化技术的容器引擎项目,整个项目基于Go语言开发,并遵从Apache 2.0协议
目前,Docker可以在容器内部快速自动化部署应用,并可以通过内核虚拟化技术 (namespaces及cgroups等)来提供容器的资源隔离与安全保障等。
由于Docker通过操作系统层的虚拟化实现隔离,所以Docker容器在运行时,不需要类 似虚拟机(VM)额外的操作系统开销,提高资源利用率,并且提升诸如IO等方面的性能。
docker本质就是进程?
A: 理解这句话得具备linux的基础知识,从基础知识角度来进行理解。首先docker的两大关键技术是Namespace和cgroup:Namespace技术改变了容器的视图,让容器以为自己在一个房间里,起到了隔离作用;cgroup(Linux Control Group)起到对容器资源的限制作用
namespace和cgroup共同为创造了一个容器沙盒。
==>容器是个进程,通过namespace作为障眼法进行屏蔽,结合cgroup进行资源限制,并以容器镜像的方式打包的一个沙盒
Docker应用场景
- web应用的自动化打包和发布
- 自动化测试和持续集成、 发布
- 在服务型环境中部署和调整数据库或其他的后台应用
- 从头编译或者扩展现有的OpenShift或Cloud Foundry平台来搭建自己的PaaS环境。
Docker优势
- 更低的资源损耗
- 更快的启动速度
- 更好的应用耦合
- 更强的弹性伸缩
Docker架构

基本要素
- Docker Images是一个只读模板,用来运行Docker容器
- Docker Containers负责应用程序的运行,包括操作系统、用户添加的文件以及元数据。
- DockerFile是文件指令集,用来说明如何自动创建Docker镜像。
核心组件

容器和镜像的关系
好比静态的源码和运行时的程序,使用执行源码即可得到想要功能的程序,同样的依据镜像从而能够构建通过镜像制定的容器。
镜像特点:
- layer: 分层
- 读写层
- init层
- 只读层
- based on another image : 基于其他镜像
- a read-only template:是只读的模板
- copy-on-write: 下层只读,上层可写
- union filesystem:有独立的文件系统
- DockerFile or docker commit:通过dockerfile或者docker commit生成
数据卷:
▲当一个容器被删除时,任何写入该容器的、没有存储在数据卷中的数据都会和该容器一起被删除。==>因此需要个可以独立于容器存储的外存。
- 数据卷不受存储驱动器的控制。
- 你可以把任何数量的数据卷装入一个容器。
- 多个容器也可以共享一个或多个数据卷
docker CLI

docker pull过程

docker run过程

Dockerfile指令说明
- FROM:初始化一个新的构建阶段,并为后续指令设置基础镜像
- ENV:为你的容器安装的软件更新PATH环境变量。
- RUN: 在容器构建过程中运行的命令,如apt。为了使你的Docker文件更易读、易懂、易维护,请将长的或复杂的RUN语句分成多行,用反斜线分开
- COPY and ADD: 复制文件到指定路径,ADD相比之下多个类似tar解压的功能
- EXPOSE: 容器将监听连接的端口
- WORKDIR: 指定工作目录,并以绝对路径的形式给出
- CMD:容器构建完成后执行命令,主要目的是为执行中的容器提供默认值。这些默认值可以包括一个可执行文件,也可以省略可执行文件,在这种情况下,你必须同时指定一个ENTRYPOINT指令。一个Docker文件中只能有一条CMD指令。如果有多个CMD,那么只有最后一个CMD才会生效。
- ENTRYPOINT:允许你配置一个将作为可执行文件运行的容器。
docker run <image>的命令行参数将被附加在exec形式的ENTRYPOINT的所有元素之后,并将覆盖所有使用CMD指定的元素。这允许将参数传递给入口点,例如,docker run-d将把-d参数传递给入口点。你可以使用docker run --entrypoint标志来覆盖ENTRYPOINT指令。
只有Docker文件中的最后一条ENTRYPOINT指令才会有效果。
Q:如何使得镜像轻量?
A:从一个合适的基础镜像开始;使用多阶段构建;如果你有多个有很多共同点的镜像,考虑用共享的组件创建你自己的基础镜像,并在此基础上创建你的独特镜像;为了保持你的生产图像的精简,但允许调试,考虑使用生产图像作为调试图像的基础图像;当建立图像时,总是用有用的tags来标记它们
云计算技术基本原理
Kubernetes核心原理与关键组件
云计算定义:云计算是一种动态扩展的计算模式,通过网络将虚拟化的资源作为服务提供

云架构图

Cloud Foundry云平台
Cloud Foundry是VMware于推出的业界第一个开源PaaS云平台,专为私有云计算环境、企业级数据中心和公有云服务提供商所打造,可以简化现代应用程序的开发、交付和运行过程,它支持多种框架、语言、运行时环境、云平台及应用服务,使开发人员能够在几秒钟内进行应用程序的部署和扩展,无需担心任何基础架构的问题。

Router
Router是整个平台的流量入口,负责分发所有的请求到对应的组件,包括来自外部用户对app的请求和平台内部的管理请求。
Router是PaaS平台中至关重要的一个组件,它在内存中维护了一张路由表,记录了域名与实例的对应关系,所谓的实例自动迁移,靠得就是这张路由表,某实例宕掉了,就从路由表中剔除,新实例创建了,就加入路由表。
状态服务
- 无状态服务在容器化的世界里很受欢迎,因为它们是一次性的,而且很容易用容器镜像重新创建。
除了像Web服务器这样的无状态服务,用户越来越多地使用容器来部署有状态服务,以受益于 “一次构建,随地运行”,并提高裸机效率/利用率。
这些 "宠物 "(需要满足的需求)带来了新的要求,包括更长的生命周期、配置依赖性和有状态的故障转移。容器编排必须解决这些需求,以成功部署和扩展应用程序。
K8s命令
K8s设计原则
- 声明式 状态驱动
用户通过声明式的配置文件(例如 YAML 文件)向 Kubernetes 告白自己希望达到的系统状态(例如:运行拥有 5 个副本的 nginx 服务)。 - 行动(React)
Kubernetes 的控制组件负责具体执行这些指令,使得用户声明的系统状态得以实现;在此过程中不需要任何人工的参与。 - 观测(Observe):
Kubernetes会观测到新的用户声明,并自动分析出需要执行的操作以达到用户声明的系统状态(例如在集群中选取5个合适的节点,并在这 5 个节点上下载合适的 nginx 镜像并启动容器,以及配置相应的负载均衡策略等)。
K8s架构
Kubernetes主要组件有:API Server、Controller Manager、Scheduler、kubelet、kube-proxy,其中前三者运行于集群的Master节点,后两者运行于集群的Worker节点。

Master
- 集群控制节点,负责集群管理与控制,通常运行在独立物理节点或者虚拟机
- 运行各类关键进程
-
API Server (kube-apiserver):提供REST接口的关键服务进程
-
集群管理的API入口
资源配额控制的入口
提供了完备的集群安全机制
-
-
Controller Manager(kube-controller-manager):所有资源的自动化控制中心
- ResourceQuota Controller
- Namespace Controller
- Endpoints Controller
-
Scheduler(Kube-scheduler):负责Pod资源调度
-
Etcd Server:所有资源对象的数据全部保存在etcd中
-
Node
Kubernetes集群中除Master外的节点,又叫Minion,同样可以是物理主机或者虚拟机
- 作为集群中的工作负载节点,承担Master分配的工作负载
Node可以动态增减,新增node会自动到master节点注册 - Node运行的进程:
- kubelet:pod启停及与master节点协作
- Ø节点管理
- ØPod管理
- Ø容器健康检查
- Ø资源监控
- kube-proxy:实现Kubenetes Service通信与负载均衡机制
- Docker Engine:负责本机容器的创建和管理工作
- kubelet:pod启停及与master节点协作
Pod:
- Pod是一组紧密关联的容器集合,是Kubernetes 调度的基本单位,不可分割。
- 一个Pod里的多个容器可以共享存储和网络,可以看作一个逻辑的主机。共享的如 namespace,cgroups或者其他的隔离资源。
创建Pod时的大概流程:
1:kubectl 向K8s API发送一个REST HTTP请求
2:调度器将其调度到一个工作节点上
3:被调度的工作节点上的kubelet会告知Node节点上的Docker engine拉取镜像,下载后运行容器。
创建pod
创建Pod可以使用两种方式,一种是通过命令行加各种命令行参数的方式,另一种是文件方式创建(推荐)
-
通过命令行直接创建:
kubectl run ${name} --image=${imageName} --port=${port}(实际是运行了一个deployment,让deployment自动创建并维护pod) -
通过yml文件创建, 文件可以为yml或者json:
kubectl apply -f ${fiileName}
删除Pods
1 | Examples: |
Pod API 对象的基本构成及书写格式

Pod各生命周期说明
- Pending:挂起,Pod已被Kubernetes系统接受,但有一个或者多个容器镜像尚未创建。 等待时间包括Pod被调度的时间和通过网络下载镜像的时间
- Running:运行中,该Pod已经绑定到了一个节点上,Pod中所有的容器都已被创建。至 少有一个容器正在运行,或者正处于启动或重启状态
- Succeeded:Pod中的所有容器都被成功终止
- Failed:失败,Pod中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也 就是说,容器以非0状态退出或者被系统终止
- Unknown:因为某些原因无法取得Pod的状态,通常是因为与Pod所在主机通信失败
- CrashLoopBackoff:Pod循环重启崩溃,通常是容器中的应用崩溃造成
pod配置
-
ImagePullPolicy
- Always:不管镜像是否存在都会进行一次拉取
- Never:不管镜像是否存在都不会进行拉取
- IfNotPresent:只有镜像不存在时,才会进行镜像拉取
-
RestartPolicy
在Pod中的容器可能会由于异常等原因导致其终止退出,Kubernetes提供了重 启策略以重启容器。重启策略对同一个Pod的所有容器起作用,容器的重启由 Node上的kubelet执行。
- Always:只要退出就重启
- OnFailure:失败退出(exit code不等于0)时重启
- Never:只要退出就不再重启
注意,这里的重启是指在Pod所在Node上面本地重启,并不会调度到其他Node上去。
-
resources
-
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15apiVersion: v1
kind: Pod
metadata:
name: tomcat
spec:
containers:
- name: tomcat
image: tomcat:8.2.59
resources:
requests:
memory: "500Mi"
cpu: "500m"
limits:
memory: "1G"
cpu: "1"
-
-
健康检查
为了确保容器在部署后确实处在正常运行状态,Kubernetes提供了两种探针(Probe)探测状态:
- LivenessProbe:探测应用是否处于健康状态,如果不健康则删除并重启容器
- ReadinessProbe:探测应用是否启动完成并且处于正常服务状态,如果不正常则不会接收来自Kubernetes Service的流量
Kubernetes支持三种方式来执行探针:
-
exec:在容器中执行一个命令,如果命令退出码返回0则表示探测成功,否则表示失败
-
tcpSocket:对指定的容器IP及端口执行一个TCP检查,如果端口是开放的则表示探测成功,否则表示失败
-
httpGet:对指定的容器IP、端口及路径执行一个HTTP Get请求,如果返回的状态码在[200,400)之间则表示探 测成功,否则表示失败
1
2
3
4
5
6
7
8
9livenessProbe:
httpGet:
path: /
port: 8080
httpHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
Probe的精确配置:
- initialDelaySeconds:容器启动后第一次执行探测是需要等待多少秒
- periodSeconds:执行探测的频率。默认是10秒,最小1秒
- timeoutSeconds:探测超时时间。默认1秒,最小1秒
- successThreshold:探测失败后,最少连续探测成功多少次才被认定为成功。默认是1 对于liveness必须是1,最小值是1
- failureThreshold:探测成功后,最少连续探测失败多少次才被认定为失败。默认是3 最小值是1
Label和Label Selector
Label
- 定义label: kubectl label ${sourceType} ${name} key=value
- 查看label: kubectl get ${type} --show-labels
- 删除label: kubectl label ${type} ${name} key-
Labels Selector:
通过标签选择器(Labels Selectors),进行查询和筛选拥有特定Label的资源对象
目前支持两种选择器:equality-based(基于平等)和set-based(基于集合)的
- Equality-based:基于相等的或者不相等的条件允许用标签的keys和values进行过滤。匹配 的对象必须满足所有指定的标签约束,尽管他们可能也有额外的标签。有三种运算符是允 许的,“=”,“==”和“!=”。前两种代表相等性(他们是同义运算符),后一种代表 非相等性,多个可用逗号隔开如,非生产nginx:environment!=production,app=nginx
- Set-based:用一组value来过滤key。支持三种操作符: In ,NotIn,Exists,DoesNotExists, 前两个value不能为空,后两个仅针对于key,没有value
labels,selector操作

Controller
controller manager 是各种controller的管理者,是集群内部的管理控制中心。
在K8S 拥有很多controller 他们的职责是保证集群中各种资源的状态和用户定义(yaml)的状态一致, 确保任何时候都在运行指定数量的Pod副本。 换句话说,Controller确保一个容器或一组相同的容器始终处于可用状态。
- ReplicationController
- ReplicaSet
- Deployments
- DaemonSet
- StatefulSets
Deployment
Deployment面向的是部署无状态应用, statefulset : 部署有状态应用
Deployment的典型应用场景
-
定义Deployment来创建Pod和ReplicaSet
-
滚动升级和回滚应用
-
`•kubectl rollout undo deployment/nginx-deployment
•deployment “nginx-deployment” rolled back`
-
-
扩容和缩容
-
暂停和继续
Kubernetes上有状态服务
- Volume
- Persistent Volume
demo:创建包含3个nginx应用pod的deployment
1 | apiVersion: extensions/v1beta1 |
-
您可以决定运行 Pod,但当它们死去时,它们就会死去。
-
部署将使您的 pod 能够连续运行。
-
部署允许您在不停机的情况下更新正在运行的应用程序。
-
部署还指定了在 Pod 死亡时重启 Pod 的策略
-
replicaSets
- Deployment 还可以创建 ReplicaSet
- ReplicaSet 可确保您的应用拥有所需数量的 Pod
- ReplicaSets 将基于 Deployment 创建和扩展 Pods
- Deployments、ReplicaSets、Pods 不是独占的,但可以是
deamonSets
- DaemonSets 用于连续进程
- 他们每个节点运行一个 Pod。
- 每个添加到集群的新节点都会启动一个 pod
- 用于监控和日志收集等后台任务
StatefulSets
-
您的应用程序是否要求您保留有关其状态的信息?
-
数据库需要状态
-
StatefulSet 的 Pod 不可互换。
-
每个 Pod 都有一个唯一的、持久的标识符,控制器在任何重新调度时都会维护该标识符。
Service详解:
-
Kubernetes中最核心的资源对象之一,Pod、RC等其实都是Service
-
Service是对一组提供相同功能的Pods的抽象,并为它们提供一个统一的入口,简单来说,可以把service理解为一个负载均衡器。借助Service,应用可以方便的实现 服务发现与负载均衡,并实现应用的稳定升级。Service通过标签来选取服务后端,一般配合Replication Controller或者Deployment来保证后端容器的正常运行。这些匹配标签的Pod IP和端口列表组成endpoints,由 kube-proxy负责将服务IP负载均衡到这些endpoints上。
-
它定义了一组Pod的逻辑集合和一个用于访问它们的策略,其实这个概念和微服务非常类似。一个Serivce下面包含的Pod集合一般是由Label Selector来决定的。
-
Service默认有自己的ip和端口的叫cluster-ip和port构成了endpoint,内部可以直接通过这个endpoint去访问应用。
- 不过有一点需要注意,这个cluster-ip是个Virtual IP,它是ping不通的,底层转发是通过node节点上的kube-proxy调用iptables生成对应的转发规则。
- ClusterIP:默认类型,自动分配一个仅cluster内部可以访问的虚拟IP
- NodePort:在ClusterIP基础上为Service在每台机器上绑定一个端口,这样就可以通过
<NodeIP>:NodePort来 访问该服务 - LoadBalancer:在NodePort的基础上,借助cloud provider创建一个外部的负载均衡器,并将请求转发到
- 不过有一点需要注意,这个cluster-ip是个Virtual IP,它是ping不通的,底层转发是通过node节点上的kube-proxy调用iptables生成对应的转发规则。
-
Service有四种类型:
- ClusterIP
- NodePort
- LoadBalancer
- ExternalName
-
Service定义
-
Service的定义也是通过yaml或json,比 如下面定义了一个名为nginx的服务, 将 服 务 的 80 端 口 转 发 到 default namespace中带有标签run=nginx的Pod 的80端口
-
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16apiVersion: v1
kind: Service
metadata:
labels:
run: nginx
name: nginx
namespace: default
spec:
ports:
- port: 80 # k8s 集群内部访问service端口, 通过cluster_ip:port 请求某个service
protocol: TCP
targetPort: 80
selector:
run: nginx
sessionAffinity: None
type: ClusterIP
-
Q: 如何访问服务?
每个Pod都提供独立的EndPoint(Pod IP + Container Port),访问请求如何映射到具体的Pod?
A: 开启负载均衡器kube-proxy,客户端通过负载均衡器调度到相应的pod,每个Service分配一个全局唯一的虚拟IP地址(Cluster IP),Pod的Endpoint地址会随着pod的销毁和创新创建而改变,但是cluster ip在Service生命周期内不会改变,因此用servcie name和cluster ip作为DNS域名,就可以解决服务访问问题
外部系统访问Service:
- Node IP: 节点IP地址,真实网络网卡的IP
- Pod IP:Pod的IP地址,根据docker0网桥的IP段进行分配,虚拟二层网络,实现Pod之间的通信
- Cluster IP: Service IP地址
- 仅服务Kubernetes Service对象
- 没有对应的实体网络,无法直接ping通
- 只能结合Service Port组成具体通信端口,集群之外无法访问
- 集群内可以使用内部路由规则进行通信,如何在外部访问?NodePort
IP和Port

见: https://zhuanlan.zhihu.com/p/358916098
各port之间的区别:
- port:k8s集群内部服务之间访问service的入口(ClusterIP:Port)
- targetPort:容器应用运行端口(最终的流量端口),如nginx是80、mysql是3306
- nodePort:外部流量访问k8s集群中service入口的一种方式(NodeIP:NodePort)
如何将服务暴露给外部客户端?
-
将服务的类型设置成NodePort
-
每个集群节点都会在节点上打开一个端口,对于NodePort服务,每个集群节点在节点本身上打开一个端口,并将在该端口上接收到的流量重定向到基础服务。所以该服务仅在内部集群IP 和端口上才可访问
-
1
2
3
4
5
6
7
8
9
10
11
12apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
type: NodePort #为NodePort设置服务类型
ports:
- port: 80 # k8s 集群内部访问service端口[服务集群IP (service cluster IP)的端口号], 通过clusterip:port 请求某个service
targetPort: 8080 # 背后Pod的目标端口号
nodePort: 30123 # 通过集群节点的30123端口可以访问该服务
selector:
app: nginx保存好yaml文件可用通过以下命令创建并且查看目标服务,
$ kubectl apply –f service.yaml,$ kubectl get svc my-service
PORT(S)列显示集群IP (80) 的内部端口和节点端口(30123)
可以通过以下地址访问该服务:10.11.254.223:80
-

- 服务暴露在两个集群节点的端口30123上,它到达任何一个端口的传入连接将都被重定向到一个随机选择的pod, 该pod是否位于接收到连接的节点上是不确定的。
- 在第一个节点的端口30123收到的连接, 可以被重定向到第一节点个上运行的 pod, 也可能是第二个节点上运行的pod
- 所以在通过节点端口访间服务之前, 有时需要配置防火墙, 来允许外部连接到该端口上的节点。
-
-
将服务的类型设置成LoadBalance(负载均衡器)
-
负载均衡器拥有自己独一无二的可公开访问的 IP 地址, 并将所有连接重定向到服务。用户可以通过负载均衡器的 IP 地址访问服务。
-
如果Kubernetes在不支持Load Balancer服务的环境中运行, 则不会调配负载平衡器, 但该服务仍将表现得像一个NodePort服务。 这是因为Load Balancer服务是NodePort服务的扩展。
-
1
2
3
4
5
6
7
8
9
10
11apiVersion: v1
kind: Service
metadata:
name: loadbalancer-service
spec:
type: LoadBalancer # 为LoadBalance设置服务类型
ports:
- port: 80 # 服务集群IP的端口号
targetPort: 8080 # 背后Pod的目标端口号
selector:
app: redis
PORT(S)列显示集群IP (80) 的内部端口和节点端口(31698)
可以通过以下地址访问该服务:10.99.34.164:80
-
-
创建一个Ingress资源
-
为什么需要 Ingress ?
-
一个重要的原因是每个 LoadBalancer 服务都需要自己的负载均衡器, 以及独有的公有IP 地址,而 Ingress 只需要一个公网 IP 就能为许多服务提供访问。 当客户端向 Ingress 发送 HTTP请求时,Ingress 会根据请求的主机名和路径决定请求转发到的服务。
-

-
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39# 单规则的 Ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test-ingress
spec:
backend: #
serviceName: test # 将所有的请求发送到test服务的80端口
servicePort: 80 #
# 根据不同路径转发到不同服务器
…
spec:
rules:
- host: website.com
http:
paths:
- path: /web
backend:
serviceName: s1
servicePort: 80
- path: /api
backend:
serviceName: s2
servicePort: 8081
# 根据不同的主机(host) 暴露出多种服务
spec:
rules:
- host: foo.bar.com
http:
paths:
- backend:
serviceName: s1
servicePort: 80
- host: bar.foo.com
http:
paths:
- backend:
serviceName: s2
servicePort: 80
-
service与deployment区别
- pod: pod 是 kubernetes 中最小的编排单位,通常由一个容器组成 (有时候会有多个容器组成)
- service: 一个网络下的pod集合。service 使用labels标签来选择代理的pod。
- Deployment:为了在 k8s 中编排应用可以更好地做弹性扩容,负载均衡,deployment 作用于一组pods的创建和运行
▲所以service 和deployment的区别,就是一个是从网络角度的抽象概念service,类型nginx做负载均衡提供的统一网络入口。而pod是最终的应用部署实体。 deoplyment 负责创建和保持pod运行状态
service 可以独立于deployment工作,但是需要一个个去创建pod,而不是像deployment那样一次性创建。deployment也可以独立于service工作。虽然service和deployment是有区别的,但不影响他们一同协同工作
ConfigMap
- ConfigMap用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件。
- 可以使用kubectl create configmap从文件、目录或者key-value字符串创建等创建 ConfigMap。也可以通过
kubectl create -f file创建。
HPA(Horizontal Pod Autoscaler)
- Kubernetes资源对象,支持Pod横向自动扩容
- Pod负载度量指标:
- CPU utilizaiton — Pod CPU利用率均值
- TPS or Qps

容器化改造过程
第一步:简单容器化,应用无改造—>效果:自动化应用上线、升级、版本回滚、监控、报警
第二步:应用去状态—> 效果:自动化故障恢复、高可用
第三步:微服务,可重用
传统单体架构缺点:
- 加载、编译耗时长
- 代码管理复杂
- 横向扩展难
- 各模块之间耦合度高
- 模块问题排查困难
微服务架构优点:
- 允许不同语言编写,易于引入新技术
- 微服务商店模式,快速组合与重构
- 模块解耦,不同的SLA保障计划
- 更高的扩展性和可用性
Kubernetes网络原理
Kubernetes网络设计主要考虑了几种通信场景
- 同一个Pod内容器间互通
- 同一个Node上Pod间互通
- Pod1与Pod2都是通过虚拟网络设备Veth, 连接到同一个docker0 bridge的,这两个 Pod的IP地址也是通过docker0网段动态分配 的,与docker0 bridge属于同一个网段。
- Pod的默认路由都是docker0 bridge的地址, 所有非本地地址的网络数据,默认都会发送 到docker0网桥上,由docker0网桥中转
- Pod与docker0之间是Veth设备对连接的,而 docker0 bridge与Node的eth0是路由转发的, Docker0上默认网关就是Node的eth0

- 不同Node上Pod间的互通
- Service与Pod之间的通信
- 实现方式为kube-proxy: 以暴露NodePort的Service为例,NodePort的工作原理与ClusterIP大致相同,发送到某个 NodeIP:NodePort的请求,通过iptables重定向到kube-proxy对应的端口(Node上的随机端口)上,然 后由kube-proxy再将请求发送到其中的一个Pod:TargetPort
- 三种proxyMode:
- Userspace Mode:v1.0及之前版本的默认模式
- Iptables Mode:v1.1开始增加支持,v1.2正式成为默认模式
- IPVS Mode:v1.8开始增加支持,v1.11正式成为默认模式
- K8s集群内外组件间通信



调用K8S服务的过程
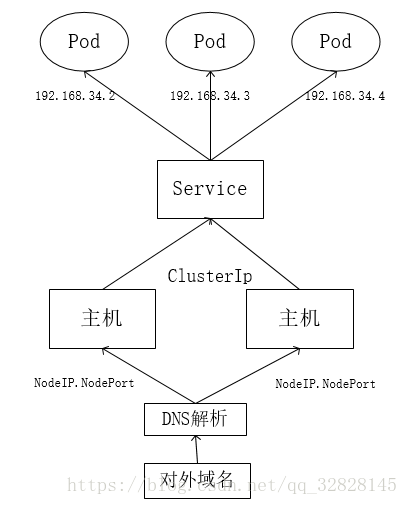
当外部client访问服务器时,首先访问服务器一致对外提供的接口,通过这一接口再将请求workload到每台主机上(每台主机上都有相对应的NodePort端口即notePort的Service来接受这一请求),每个service服务上都有一个对应的ClusterIP,通过ClusterIP和每台主机上的IPTables表以及label筛选,service就可以将请求workload到具体的每个pod上(endpoint)。
附录:
Vscode环境配置
- docker插件下载:
- k8s插件下载:
Author: Mrli
Link: https://nymrli.top/2021/09/25/ZJU云原生技术及应用-课程笔记/
Copyright: All articles in this blog are licensed under CC BY-NC-SA 3.0 unless stating additionally.