
Python爬虫常规流程
以爬取有道翻译为例子。
挖取可自用的API
web 端的有道翻译,在之前是直接可以爬的。也就是说只要获取到了他的接口,你就可以肆无忌惮的使用他的接口进行翻译而不需要支付任何费用。那么自从有道翻译推出他的API服务的时候,就对这个接口做一个反爬虫机制(如果大家都能免费使用到他的翻译接口,那他的APl服务怎么赚钱)。这个反爬虫机制在爬虫领域算是一个非常经典的技术手段。
1.查看要爬取的内容是否是静态加载的。
比如在翻译输入框中输入apple,翻译输出框中会出现苹果,然后在``页面中右键->查看网页源代码,直接Ctrl+F搜索是否存在apple或者苹果`,如果没有的话,证明不是静态加载的。
2.查看内容如何加载的
- 页面初始化get、post请求
- 局部刷新发送ajax请求
- 如果存在局部更新内容产生变化的(Url没有发生变化,或者没有页面发生跳转、刷新的感觉),一般都是采用的AJAX更新技术,发送了POST、GET请求获得局部需要更新的数据,可以直接在Network项的XHR里面找到动态加载的文件 (可以看下Ajax技术实现了解下为什么可以在XHR中找到)
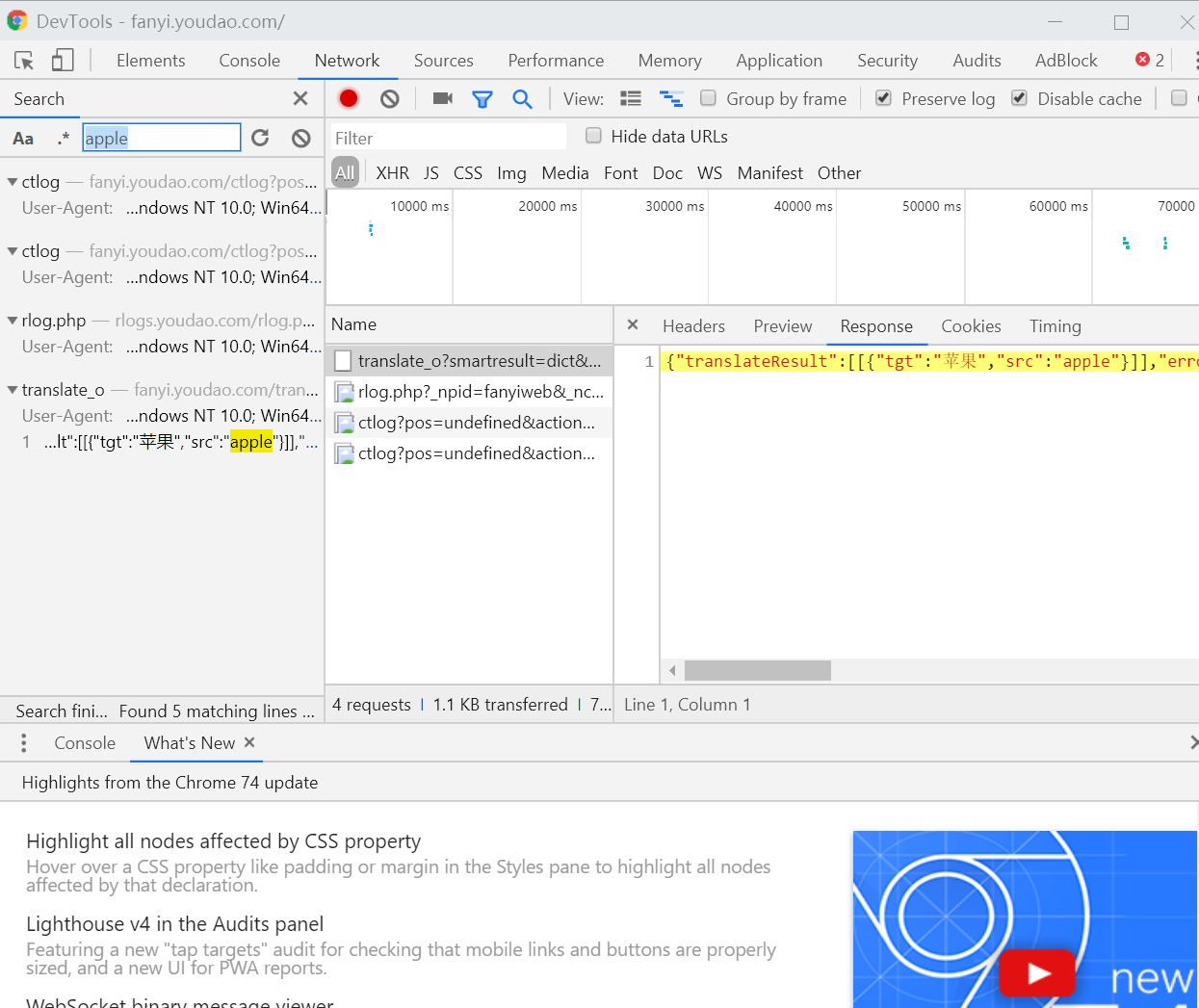
这边的话,可以看到输入一个要翻译的内容后,页面没有产生多大的变化,因此猜想是AJAX加载的。在XHR里也找到了相应的Response文件。
使用Chrome自带的抓包工具(页面中右键->检查或者按F12都可以打开,然后选择->Network项(网络监听窗口)就可以看到抓包的数据了)
然后同样在翻译输入框中输入apple,然后可以观察到抓包工具中出现了很多内容。为了确定apple的翻译苹果是在哪个文件中返回的,可以直接Ctrl+F打开搜索框后直接搜索,如图所示。
JS加密破解
1.使用Python进行模仿JS加密计算
2.运行JS代码获得加密结果
- 使用python-js2py模块
如一个参数生成的结果是这样的{"LoginKey":"46fd82c2-3108-b2a4-3056-0eaa426f975b","data":"{/"User_Oid/":/"账号/",/"User_Password/":/"密码/"}"}
找到生成LoginKey值的JS文件加密算法是这样的:
1 | function s4() { |
然后安装pip install js2py后
1 | #coding=utf-8 |
就能获得结果了。
- 使用pyexe、PyV8、js2py模块
1 | import execjs |
js2py
1 | import js2py |
逐步确定JS对密码的加密逻辑 ==> 定位到加密函数
两种思路
-
全局搜索password字段
-
全局搜加密算法的名字
加密一般都是JS加密,加密算法一般比较出名的就那么几个,比如
MD5,base64,aes(对称密码),rsa(非对称加密算法)都是可以用来加密的,你可以全局搜这些加密算法的名字
https://www.jianshu.com/p/055e1ddf7bb2
rsa加密
对极大整数做因数分解的难度决定了RSA算法的可靠性。换言之,对一极大整数做因数分解愈困难,RSA算法愈可靠。假如有人找到一种快速因数分解的算法的话,那么用RSA加密的信息的可靠性就肯定会极度下降。但找到这样的算法的可能性是非常小的。今天只有短的RSA钥匙才可能被强力方式解破==>为什么密码要大于6位。到目前为止,世界上还没有任何可靠的攻击RSA算法的方式。只要其钥匙的长度足够长,用RSA加密的信息实际上是不能被解破的。
Author: Mrli
Link: https://nymrli.top/2019/08/30/Python爬虫常规流程/
Copyright: All articles in this blog are licensed under CC BY-NC-SA 3.0 unless stating additionally.