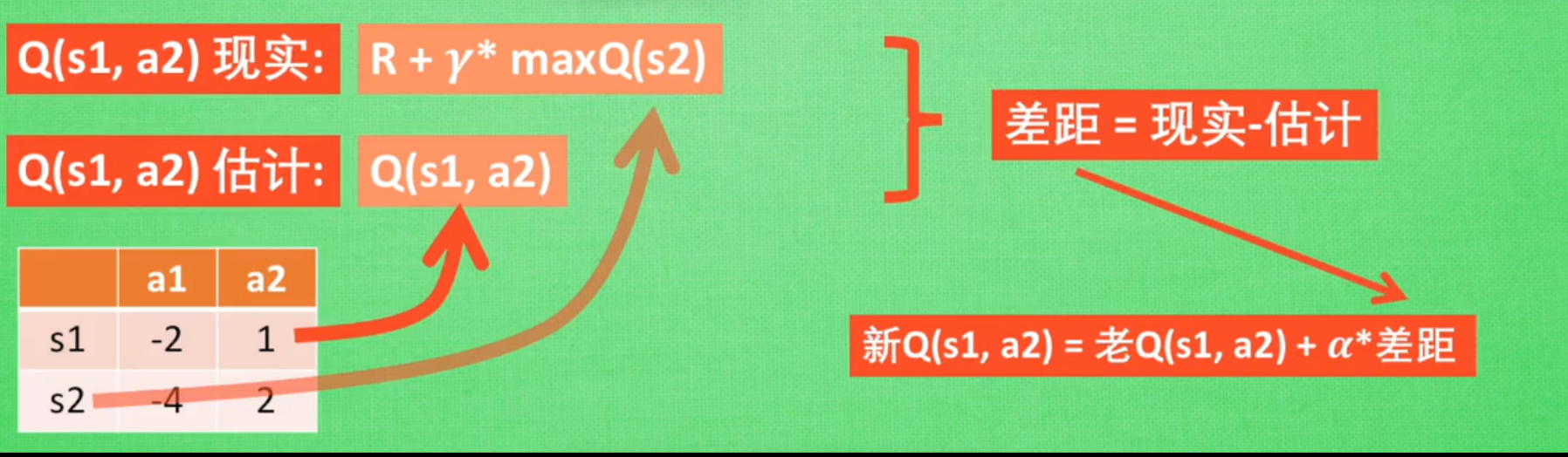
价值转移公式只有一条Q ( s , a ) < = Q ( s , a ) + / a l p h a ∗ ( r e w a r d − Q ( s , a ) + / g a m m a ∗ m a x a Q ( s ′ , a ) ) = ( 1 − / a l p h a ) ∗ Q ( s , a ) + / a l p h a ∗ ( r e w a r d + / g a m m a ∗ m a x a Q ( s ′ , a ) ) Q(s,a) <= Q(s,a) + /alpha*(reward - Q(s,a) + /gamma*max_aQ(s',a)) = (1-/alpha)*Q(s,a) + /alpha*(reward + /gamma*max_aQ(s',a)) Q ( s , a ) < = Q ( s , a ) + / a l p h a ∗ ( r e w a r d − Q ( s , a ) + / g a m m a ∗ m a x a Q ( s ′ , a ) ) = ( 1 − / a l p h a ) ∗ Q ( s , a ) + / a l p h a ∗ ( r e w a r d + / g a m m a ∗ m a x a Q ( s ′ , a ) ) 新 Q ( s 1 , a 2 ) = 老 Q ( s 1 , a 2 ) + / a l p h a ∗ 差 距 ( 现 实 − 估 计 ) 新Q(s1,a2) = 老Q(s1,a2) + /alpha * 差距(现实-估计) 新 Q ( s 1 , a 2 ) = 老 Q ( s 1 , a 2 ) + / a l p h a ∗ 差 距 ( 现 实 − 估 计 )
ALPHA为学习率,设置估计与现实的差距 有多少被学习。能够使得更新比较平缓,防止模型过早收敛到局部解
如果有两种途径都能得到Reward宝藏,如果直接设置1,那么很大程度上,算法都会沿着已尝试出有Reward的路走,虽然有E-Greedy的探索,但是那样的得分可能不至于让第二条路成为更优的选择。所以设置学习率有助于找到第二条路。
GAMMA为衰减系数,m a x a Q ( s ′ , a ) max_aQ(s',a) m a x a Q ( s ′ , a ) Q ( s 1 ) = r 2 + / g a m m a Q ( s 2 ) = r 2 + / g a m m a ( r 3 + / g a m m a Q ( S 3 ) ) = . . . = r 2 + / g a m m a ∗ r 3 + / g a m m a 2 ∗ r 4 + / g a m m a 3 r 5 + . . . Q(s1) = r2 + /gamma Q(s2) = r2 + /gamma(r3+/gamma Q(S3)) = ...= r2 + /gamma *r3+/gamma^{2} *r4+ /gamma^{3} r5 + ... Q ( s 1 ) = r 2 + / g a m m a Q ( s 2 ) = r 2 + / g a m m a ( r 3 + / g a m m a Q ( S 3 ) ) = . . . = r 2 + / g a m m a ∗ r 3 + / g a m m a 2 ∗ r 4 + / g a m m a 3 r 5 + . . .
GAMMA == 1时,Agent能看到之后所有步的奖励。
只不过真正的理解应该时反序的,即最后一步是得到最终的reward,然后之前的状态的动作选择回报是在这个最终的reward上不断乘以GAMMA进行衰减,使得S1的选择不至于被最后的选择而过多影响
GAMMA == 0时,Agent只能看到眼前的奖励
▲需要注意的是,这个公式是更新公式,而不是等式,因此两边不能化简,用代码来表示就是Q[state, action] = (1-ALPHA)*Q[state, action] + ALPHA*(reward + GAMMA*Q[newstate, action].max())
环境代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 from __future__ import print_functionimport copyMAP = / ''' ......... . . . o . . . ......... ''' MAP = MAP.strip().split('/n' ) MAP = [[c for c in line] for line in MAP] DX = [-1 , 1 , 0 , 0 ] DY = [0 , 0 , -1 , 1 ] class Env (object) : def __init__ (self) : self.map = copy.deepcopy(MAP) self.x = 1 self.y = 1 self.step = 0 self.total_reward = 0 self.is_end = False def interact (self, action) : assert self.is_end is False new_x = self.x + DX[action] new_y = self.y + DY[action] new_pos_char = self.map[new_x][new_y] self.step += 1 if new_pos_char == '.' : reward = 0 elif new_pos_char == ' ' : self.x = new_x self.y = new_y reward = 0 elif new_pos_char == 'o' : self.x = new_x self.y = new_y self.map[new_x][new_y] = ' ' self.is_end = True reward = 100 elif new_pos_char == 'x' : self.x = new_x self.y = new_y self.map[new_x][new_y] = ' ' reward = -5 self.total_reward += reward return reward @property def state_num (self) : rows = len(self.map) cols = len(self.map[0 ]) return rows * cols @property def present_state (self) : cols = len(self.map[0 ]) return self.x * cols + self.y def print_map (self) : printed_map = copy.deepcopy(self.map) printed_map[self.x][self.y] = 'A' print('/n' .join(['' .join([c for c in line]) for line in printed_map])) def print_map_with_reprint (self, output_list) : printed_map = copy.deepcopy(self.map) printed_map[self.x][self.y] = 'A' printed_list = ['' .join([c for c in line]) for line in printed_map] for i, line in enumerate(printed_list): output_list[i] = line
Agent代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 from __future__ import print_functionimport numpy as npimport timefrom env import EnvEPSILON = 0.1 ALPHA = 0.1 GAMMA = 0.9 MAX_STEP = 30 np.random.seed(0 ) def epsilon_greedy (Q, state) : if (np.random.uniform() > 1 - EPSILON) or ((Q[state, :] == 0 ).all()): action = np.random.randint(0 , 4 ) else : action = Q[state, :].argmax() return action e = Env() Q = np.zeros((e.state_num, 4 )) for i in range(200 ): e = Env() while (e.is_end is False ) and (e.step < MAX_STEP): action = epsilon_greedy(Q, e.present_state) state = e.present_state reward = e.interact(action) new_state = e.present_state Q[state, action] = (1 - ALPHA) * Q[state, action] + / ALPHA * (reward + GAMMA * Q[new_state, :].max()) e.print_map() time.sleep(0.1 ) print('Episode:' , i, 'Total Step:' , e.step, 'Total Reward:' , e.total_reward) time.sleep(2 )
环境代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 from __future__ import print_functionimport copymaze = / ''' .......... . . . o . . . .......... ''' maze = maze.strip().split('/n' ) MAP = [[col for col in line] for line in maze] DX = [-1 , 0 , 1 , 0 ] DY = [0 , 1 , 0 , -1 ] class Env (object) : ''' 交互环境 ''' def __init__ (self) : self.map = copy.deepcopy(MAP) self.x = 1 self.y = 1 self.step = 0 self.isEnd = False self._score = 0 def interact (self, action) : newx = self.x + DX[action] newy = self.y + DY[action] newPos = self.map[newx][newy] self.step += 1 if newPos == '.' : reward = -10 elif newPos == ' ' : self.x = newx self.y = newy reward = 2 elif newPos == 'o' : self.x = newx self.y = newy reward = 100 self.isEnd = True self._score += reward return reward @property def state_num (self) : rows = len(self.map) cols = len(self.map[0 ]) return rows * cols @property def score (self) : return self._score @property def present_state (self) : return len(self.map[0 ])*self.x + self.y def printMap (self) : printed_map = copy.deepcopy(self.map) printed_map[self.x][self.y] = 'A' print('/n' .join(['' .join([c for c in line]) for line in printed_map])) if __name__ == '__main__' : e = Env() e.printMap() print(e.score)
碰到边界'.'时,将会扣分
如果没有任何事发生的话,那么奖励2分
修改后结果如下
Agent代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 from __future__ import print_functionimport numpy as npfrom pprint import pprintfrom env import Envimport timeEPSILON = 0.2 ALPHA = 0.1 GAMMA = 0.9 MAX_STEP = 30 TIMES = 30 def epsilonGreedy (Q, state) : if np.random.uniform() > 1 -EPSILON or ((Q[state, :] == 0 ).all()): action = np.random.randint(0 ,4 ) else : action = Q[state, :].argmax() return action e = Env() np.random.seed(0 ) Q = np.zeros((e.state_num, 4 )) success = 0 for i in range(TIMES): ne = Env() while (ne.isEnd == False ) and (ne.step < MAX_STEP): state = ne.present_state action = epsilonGreedy(Q, state) print(action) reward = ne.interact(action) newstate = ne.present_state if ne.map[newstate//10 ][newstate%10 ] == 'o' : success += 1 print('success=' ,success) print("结果为:" ) ne.printMap() print("再下一步的得分:" ,Q[newstate,:]) Q[state, action] = (1 -ALPHA)*Q[state, action] + / ALPHA*(reward + GAMMA*Q[newstate, action].max()) time.sleep(.05 ) print('Episode:' , i, 'Total Step:' , ne.step, 'Total Reward:' , ne.score) time.sleep(2 ) print(Q) print(success)
走" "得奖励值设为+2得情况下,当EPSILON=0.1时,30次训练,几乎都在起点左右摇摆。
原因是没碰到宝藏前,他们这样漫无目的的走是得分最高的。
处理的方法:1.修改Epsilon值,让他们有更多的机会去探索;2.增大训练的次数,一旦他们曾经到过宝藏,那么他们会往这个好的方向优化
注意 ,如果设置" "的奖励的话,需要慎重考虑,因为左右摇摆最高的奖励值在MAX_STEP=30的情况下是能达到60的。所以宝藏的奖励值一定要略大于MAX_SETP*EMPTY_REWARD 才能达到训练的目的;同时,可能导致找不到最快寻到宝藏的可能 ,比如在宝藏门前来回晃悠来获得" "奖励->解决方案:可以根据当前步数来设置宝藏的分数 碰到'.'扣分,使得Agent不倾向于撞墙,这个是个不错的修改,从Q表中也能看到明显的效果。但是一旦之后出现有陷阱的情况"X",那么这边的惩罚值得设定需要慎重考虑
环境代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 from __future__ import print_functionimport copyTREASURE = 'o' TRAP = 'X' maze = / ''' .......... . {trap} . . {treasure} . . . .......... ''' .format(treasure=TREASURE,trap=TRAP)maze = maze.strip().split('/n' ) MAP = [[col for col in line] for line in maze] DX = [-1 , 0 , 1 , 0 ] DY = [0 , 1 , 0 , -1 ] class Env (object) : ''' 交互环境 ''' def __init__ (self) : self.map = copy.deepcopy(MAP) self.x = 1 self.y = 1 self.step = 0 self.isEnd = False self._score = 0 def interact (self, action) : newx = self.x + DX[action] newy = self.y + DY[action] newPos = self.map[newx][newy] self.step += 1 if newPos == '.' : reward = -10 elif newPos == ' ' : self.x = newx self.y = newy reward = 2 elif newPos == 'o' : self.x = newx self.y = newy reward = 100 self.isEnd = True elif newPos == 'X' : self.x = newx self.y = newy reward = -50 self.isEnd = True self._score += reward return reward @property def state_num (self) : rows = len(self.map) cols = len(self.map[0 ]) return rows * cols @property def score (self) : return self._score @property def present_state (self) : return len(self.map[0 ])*self.x + self.y def printMap (self) : printed_map = copy.deepcopy(self.map) printed_map[self.x][self.y] = 'A' print('/n' .join(['' .join([c for c in line]) for line in printed_map])) if __name__ == '__main__' : e = Env() e.printMap() print(e.score)
Agent代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 from __future__ import print_functionimport numpy as npfrom pprint import pprintfrom env import Envimport timeEPSILON = 0.2 ALPHA = 0.1 GAMMA = 0.9 MAX_STEP = 30 TIMES = 40 TEST_TIMES = 5 def epsilonGreedy (Q, state) : if np.random.uniform() > 1 -EPSILON or ((Q[state, :] == 0 ).all()): action = np.random.randint(0 ,4 ) else : action = Q[state, :].argmax() return action e = Env() np.random.seed(0 ) Q = np.zeros((e.state_num, 4 )) def Qtrain () : success = 0 for i in range(TIMES): ne = Env() while (ne.isEnd == False ) and (ne.step < MAX_STEP): state = ne.present_state action = epsilonGreedy(Q, state) print("当前的选择为:" ,action) reward = ne.interact(action) newstate = ne.present_state if ne.map[newstate//10 ][newstate%10 ] == 'o' : success += 1 print('success=' ,success) print("结果为:" ) ne.printMap() print("再下一步的得分:" ,Q[newstate,:],'/n' ) Q[state, action] = (1 -ALPHA)*Q[state, action] + / ALPHA*(reward + GAMMA*Q[newstate, action].max()) time.sleep(.05 ) print('Episode:' , i, 'Total Step:' , ne.step, 'Total Reward:' , ne.score) print('-' *20 , '/n/n' ) time.sleep(2 ) print(Q) print(success) def Qtest () : print('*' *10 ,"开始测试" ,'*' *10 ) for i in range(TEST_TIMES): ne = Env() while (ne.isEnd == False ) and (ne.step < MAX_STEP): state = ne.present_state action = Q[state,:].argmax() print("当前的选择为:" ,action) reward = ne.interact(action) newstate = ne.present_state print("结果为:" ) ne.printMap() print("再下一步的得分:" ,Q[newstate,:],'/n' ) time.sleep(.05 ) print('Episode:' , i, 'Total Step:' , ne.step, 'Total Reward:' , ne.score) print('-' *20 ,'/n/n' ) time.sleep(2 ) if __name__ == '__main__' : Qtrain() Qtest()
由于走空" "现象仍然存在,感觉奖励给2仍是太多
EPSILON=0.2,随机乱走的几率很高,导致开局踩到陷阱X的概率很大
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 ********** 开始测试 ********** 当前的选择为: 2 结果为: .......... . X . .A o . . . .......... 再下一步的得分: [ 0.12753822 0. 1.0434062 -2.9701 ] 当前的选择为: 2 结果为: .......... . X . . o . .A . .......... 再下一步的得分: [ 0.21147844 2.30159071 0. -1.99 ] 当前的选择为: 1 结果为: .......... . X . . o . . A . .......... 再下一步的得分: [-0.313 0.398 -1. 1.04984339] 当前的选择为: 3 结果为: .......... . X . . o . .A . .......... 再下一步的得分: [ 0.21147844 2.30159071 0. -1.99 ] 当前的选择为: 1 结果为: .......... . X . . o . . A . .......... 再下一步的得分: [-0.313 0.398 -1. 1.04984339] ... 之后都是1和3的循环选择
可以看到,这边上下变成了死循环。这是当所有训练中都没有踩到过宝藏的情况。
▲.使训练中更有可能碰到宝藏的方法
训练的次数T足够多
如果训练次数少的话,需要合理设置EPSILON,使得Agent有更多的机会探索
MAX_STEP设置合理
▲.还有一点要说明的是:Q:有种情况是,同样都是走空得2分,为什么向上得得分是18,而向右得得分是2呢?
A:因为Dx,Dy的循序(上右下左)决定了。当四个得分都一样时如[2,2,2,2],那么将会优先选择上 ,因为如果走空有奖励,所以上比右的得分会高很多。
1 2 3 4 5 6 7 8 9 10 11 DX = [-1 , 0 , 1 , 0 ] DY = [0 , 1 , 0 , -1 ] def epsilonGreedy (Q, state) : if np.random.uniform() > 1 -EPSILON or ((Q[state, :] == 0 ).all()): action = np.random.randint(0 ,4 ) else : action = Q[state, :].argmax() return action
即
1 2 3 4 5 6 7 8 9 10 11 12 13 a = np.array([ [1 ,0 ,1 ,1 ], [2 ,1 ,3 ,1 ] ]) print(a[0 ,:].argmax()) a = np.array([ [1 ,0 ,3 ,3 ], [2 ,1 ,3 ,1 ] ]) print(a[0 ,:].argmax())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 当前的选择为: 2 结果为: .......... . X . .A o . . . .......... 再下一步的得分: [-0.501399 23.9585123 0. -3.940399 ] 当前的选择为: 1 结果为: .......... . X . . A o . . . .......... 再下一步的得分: [-20.4755 41.20097133 0. -0.267309 ] 当前的选择为: 1 结果为: .......... . X . . A o . . . .......... 再下一步的得分: [-0.457659 66.18493075 -0.2439 0. ] 当前的选择为: 1 结果为: .......... . X . . Ao . . . .......... 再下一步的得分: [ 0. 94.1850263 0. 0. ] 当前的选择为: 1 结果为: .......... . X . . A . . . .......... 再下一步的得分: [0. 0. 0. 0.] Episode: 4 Total Step: 5 Total Reward: 100 --------------------
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 当前的选择为: 2 结果为: .......... . X . .A o . . . .......... 再下一步的得分: [-0.41254159 6.24693379 -0.03645728 -3.940399 ] 当前的选择为: 1 结果为: .......... . X . . A o . . . .......... 再下一步的得分: [-9.5 21.14440154 0.2981 0. ] 当前的选择为: 1 结果为: .......... . X . . A o . . . .......... 再下一步的得分: [ 5.16800000e-01 5.26069497e+01 -3.14898100e-02 3.80000000e-01] 当前的选择为: 1 结果为: .......... . X . . Ao . . . .......... 再下一步的得分: [ 0.45506025 83.3228183 1.0434062 2.28281481] 当前的选择为: 1 结果为: .......... . X . . A . . . .......... 再下一步的得分: [0. 0. 0. 0.] Episode: 4 Total Step: 5 Total Reward: 108 --------------------