gym开源库:包含一个测试问题集,每个问题成为环境(environment),可以用于自己的RL算法开发。这些环境有共享的接口,允许用户设计通用的算法。其包含了deep mind 使用的Atari游戏测试床。
在强化学习中有2个基本概念,一个是环境(environment),称为外部世界,另一个为智能体agent(写的算法 )。agent发送action至environment,environment返回观察和回报。
Gym官方文档
1 2 3 4 5 6 7 8 9 import gymenv = gym.make(‘CartPole-v0’) env.reset() for _ in range(1000 ): env.render() env.step(env.action_space.sample())
设计理念图,一个环境的step函数返回需要的信息,有4种返回值
observation reward done :判断是否到了重新设定(reset )环境info :用于调试的诊断信息,有时也用于学习,但智能体(agent )在正式的评价中不允许使用该信息进行学习。
该进程通过调用reset()来启动,它返回一个初始 observation 。 所以之前代码的更恰当的方法是遵守done 的标志:
在上面的例子中,已经从环境的动作空间中抽取随机动作。但这些行动究竟是什么呢? 每个环境都带有action_space 和observation_space 对象。这些属性是Space 类型,它们描述格式化的有效的行动和观察。
1 2 3 4 5 6 7 import gymenv = gym.make('CartPole-v0' ) print(env.action_space) print(env.observation_space)
Box空间表示一个n维box,所以有效的观察将是4个数字的数组。 也可以检查Box的范围:
1 2 3 4 print(env.observation_space.high) print(env.observation_space.low)
这种内省可以帮助编写适用于许多不同环境的通用代码。box和discrete是最常见的空间。你可以从一个空间中取样,或者检查某物是否属于它:
1 2 3 4 5 from gym import spacesspace = spaces.Discrete(8 ) x = space.sample() assert space.contains(x)assert space.n == 8
参考Gym 简单画图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import gymfrom gym.envs.classic_control import renderingclass Test (gym.Env) : metadata = { 'render.modes' : ['human' , 'rgb_array' ], 'video.frames_per_second' : 2 } def __init__ (self) : self.viewer = rendering.Viewer(600 , 400 ) def render (self, mode='human' , close=False) : line1 = rendering.Line((100 , 300 ), (500 , 300 )) line2 = rendering.Line((100 , 200 ), (500 , 200 )) line1.set_color(0 , 0 , 0 ) line2.set_color(0 , 0 , 0 ) self.viewer.add_geom(line1) self.viewer.add_geom(line2) return self.viewer.render(return_rgb_array=mode == 'rgb_array' ) if __name__ == '__main__' : t = Test() while True : t.render()
△.值得注意的是,画板的水平方向是 x 轴, 垂直方向是 y 轴, 且原点在左下角
画个圆 1 2 3 4 5 6 7 8 9 10 11 def render (self, mode='human' , close=False) : circle = rendering.make_circle(30 ) circle_transform = rendering.Transform(translation=(100 , 200 )) circle.add_attr(circle_transform) self.viewer.add_geom(circle) return self.viewer.render(return_rgb_array=mode == 'rgb_array' )
△注意.是圆心在平移
研究rings时写的render
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 import gymfrom gym.envs.classic_control import renderingimport timeimport numpy as npimport randomclass ringViewer (rendering.Viewer) : ''' 画板,直接继承自rendering.Viewer ''' def __init__ (self,width, height, display=None) : super(ringViewer, self).__init__(width, height, display=None ) @staticmethod def pos2loc (pos=0 ) : ''' 根据位置索引确定画图坐标 :param pos: 位置索引0-9 :return: loc ''' pass @staticmethod def getSize (size) : ''' 设置画圆的半径 :param size:[0-2] :return: radius ''' pass @staticmethod def getColor (c=0 ) : ''' 根据颜色索引选择圆圈颜色 :param c: :return: list ''' pass def drawNewring (self, newring:list=None) : ''' 画新生成的圆 :param newring: :return: ''' for i in range(len(newring)): if newring[i] != 0 : ring = rendering.make_circle(radius=self.getSize(i), res=50 , filled=False ) r, g, b = self.getColor(newring[i]) ring.set_color(r, g, b) ring_transform = rendering.Transform(translation=(150 ,30 )) ring.add_attr(ring_transform) self.add_geom(ring) def _drawQG (self, qgs: list=None) : ''' 画棋盘上各个棋格的圆圈 :param qgs: :return: None ''' for num,qg in enumerate(qgs): for i in range(len(qg)): if qg[i] != 0 : ring = rendering.make_circle(radius=self.getSize(i), res = 50 , filled=False ) r, g, b = self.getColor(qg[i]) ring.set_color(r, g, b) ring_transform = rendering.Transform(translation=self.pos2loc(num)) ring.add_attr(ring_transform) self.add_geom(ring) def getQG (self, qg: list=None) : ''' 将len=27的list转换为[[],[],...] :param qg: (27,1)的list :return: (9,1)的list ''' qgs = [] for x in range(3 ): for y in range(3 ): tmp = [] for z in range(3 ): tmp.append(qg[9 *x+3 *y+z]) qgs.append(tmp) self._drawQG(qgs) class Testenv (gym.Env) : metadata = { 'render.modes' : ['human' , 'rgb_array' ], 'video.frames_per_second' : 2 } def __init__ (self) : self.viewer = ringViewer(300 , 400 ) self.state:list = [] self.state:list = [] def setState (self, state) : self.state = state def setNewring (self, newring=None) : self.newring = newring def render (self, mode='human' , close=False) : if self.state.any(): self.viewer.geoms.clear() self.viewer.onetime_geoms.clear() self.viewer.getQG(self.state) if self.newring: self.viewer.drawNewring(self.newring) return self.viewer.render(return_rgb_array=mode == 'rgb_array' ) if __name__ == '__main__' : v = Testenv() while True : v.setState(np.random.randint(0 ,6 ,(27 ))) v.setNewring([random.randint(0 ,5 ) for x in range(3 )]) print(v.state) print(v.newring) v.render() time.sleep(2 )
△.由于没有找到viewer源码中删除组件的代码,于是每次在渲染前 清空上一次geoms和onetime_geoms列表 来达到消除的目的
效果图如下
由于该博客的代码展示实在太乱,于是重新帮他排版了一下
我们继续讲,从第1小节的尾巴开始。有三个重要的函数:
env = gym.make(‘CartPole-v0’)
env.reset()
env.render()
第一个函数是创建环境,我们会在第3小节具体讲如何创建自己的环境,所以这个函数暂时不讲。第二个函数env.reset()和第三个函数env.render()是每个环境文件都包含的函数。我们以cartpole为例,对这两个函数进行讲解。
Cartpole的环境文件在~你的gym目录/gym/envs/classic_control/cartpole.py.
该文件定义了一个CartPoleEnv的环境类,该类的成员函数有:seed(), step(),reset()和render(). 第1小节调用的就是CartPoleEnv的两个成员函数reset()和render()。下面,我们先讲讲这两个函数,再介绍step()函数
reset()为重新初始化函数。那么这个函数有什么用呢?
在强化学习算法中,智能体需要一次次地尝试,累积经验,然后从经验中学到好的动作。一次尝试我们称之为一条轨迹或一个episode. 每次尝试都要到达终止状态. 一次尝试结束后,智能体需要从头开始,这就需要智能体具有重新初始化 的功能。函数reset()就是这个作用。
reset()的源代码为:
1 2 3 4 5 6 7 def _reset () # 利用均匀随机分布初试化环境的状态 self.state = self.np_random.uniform(low=-0.05, high=0.05, size=(4,)) self.steps_beyond_done = None return np.array(self.state)
render()函数在这里扮演图像引擎 的角色。一个仿真环境必不可少的两部分是物理引擎 和图像引擎 。物理引擎模拟环境中物体的运动规律;图像引擎用来显示环境中的物体图像。其实,对于强化学习算法,该函数可以没有。但是,为了便于直观显示当前环境中物体的状态,图像引擎还是有必要的。另外,加入图像引擎可以方便我们调试代码。下面具体介绍gym如何利用图像引擎来创建图像。
我们直接看源代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from gym.envs.classic_control import renderingclass myenv (gym.Env) def _render (self, mode=’human’, close=False) : if close: pass if self.viewer is None : self.viewer = rendering.Viewer(screen_width, screen_height) l,r,t,b = -cartwidth/2 , cartwidth/2 , cartheight/2 , -cartheight/2 axleoffset =cartheight/4.0 cart = rendering.FilledPolygon([(l,b), (l,t), (r,t), (r,b)])
创建完cart的形状,接下来给cart添加平移属性和旋转属性。将车的位移设置到cart的平移属性中,cart就会根据系统的状态变化左右运动。具体代码解释,我已上传到github上面了,gxnk/reinforcement-learning-code 。想深入了解的同学可去下载学习。
该函数在仿真器中扮演物理引擎 的角色。其输入是动作a,输出是:下一步状态,立即回报,是否终止,调试项。
该函数描述了智能体与环境交互的所有信息,是环境文件中最重要的函数。在该函数中,一般利用智能体的运动学模型和动力学模型计算下一步的状态和立即回报,并判断是否达到终止状态。
我们直接看源代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def _step (self, action) : assert self.action_space.contains(action), "%r (%s) invalid" %(action, type(action)) state = self.state x, x_dot, theta, theta_dot = state force = self.force_mag if action==1 else -self.force_mag costheta = math.cos(theta) sintheta = math.sin(theta) temp = (force + self.polemass_length * theta_dot * theta_dot * sintheta) / self.total_mass thetaacc = (self.gravity * sintheta - costheta* temp) / (self.length * (4.0 /3.0 - self.masspole * costheta * costheta / self.total_mass)) xacc = temp - self.polemass_length * thetaacc * costheta / self.total_mass x = x + self.tau * x_dot x_dot = x_dot + self.tau * xacc theta = theta + self.tau * theta_dot theta_dot = theta_dot + self.tau * thetaacc self.state = (x,x_dot,theta,theta_dot)
2.4 一个简单的demo
下面,我给出一个最简单的demo,让大家体会一下上面三个函数如何使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import gymimport timeenv = gym.make('CartPole-v0' ) count = 0 for t in range(100 ): action = env.action_space.sample() observation, reward, done, info = env.step(action) if done: break env.render() count+=1 time.sleep(0.2 ) print(count)
第3小节:创建自己的gym环境并利示例qlearning的方法
在上一小节中以cartpole为例子深入剖析了gym环境文件的重要组成。我们知道,一个gym环境最少的组成需要包括reset()函数和step()函数。当然,图像显示函数render()一般也是需要的。这一节,我会以机器人找金币为例给大家演示如何构建一个全新的gym环境,并以此环境为例,示例最经典的强化学习算法qlearning算法。在3.1节中,给出机器人找金币的问题陈述;第3.2节中,给出构建gym环境的过程;第3.3节中,利用qlearning方法实现机器人找金币的智能决策。全部代码已传到github上。
3.1 机器人找金币的问题陈述
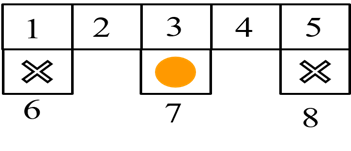
图1.1 机器人找金币
如图1.1 为机器人在网格世界找金币的示意图。该网格世界一共有8个状态,其中状态6和状态8为死亡区域,状态7为金币区域。机器人的初始位置为网格世界中任意一个状态。机器人从初始状态出发寻找金币。机器人进行一次探索,进入死亡区域或找到金币,本次探测结束。机器人找到金币的回报为1,进入死亡区域回报为-1,机器人在区域1-5之间转换时,回报为0。我们的目标是找到一个策略使得机器人不管处在什么状态(1-5)都能找到金币。对于这个机器人找金币的游戏,我们可以利用强化学习的方法来实现。
该例子的代码,除了本篇博客有以外,OpenAI Gym构建自定义强化学习环境 有更仔细和规范的代码贴出
一个gym的环境文件,其主体是个类,在这里我们定义类名为:GridEnv, 其初始化为环境的基本参数,因为机器人找金币的过程是一个马尔科夫过程,我们在强化学习入门课程的第一讲已经介绍过了一个马尔科夫过程应该包括状态空间,动作空间,回报函数,状态转移概率。因此,我们在类GridEnv的初始化时便给出了相应的定义。网格世界的全部代码在gxnk/reinforcement-learning-code ,文件名为 grid_mdp.py. 我们看源代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 self.states = [1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ] self.actions = ['n' ,'e' ,'s' ,'w' ] self.rewards = dict(); self.rewards['1_s' ] = -1.0 self.rewards['3_s' ] = 1.0 self.rewards['5_s' ] = -1.0 self.t = dict(); self.t['1_s' ] = 6 self.t['1_e' ] = 2 self.t['2_w' ] = 1 self.t['2_e' ] = 3 self.t['3_s' ] = 7 self.t['3_w' ] = 2 self.t['3_e' ] = 4 self.t['4_w' ] = 3 self.t['4_e' ] = 5 self.t['5_s' ] = 8 self.t['5_w' ] = 4
有了状态空间,动作空间和状态转移概率,我们便可以写step(a)函数了。这里特别注意的是,step()函数的输入是动作,输出为:下一个时刻的动作,回报,是否终止,调试信息。尤其需要注意的是输出的顺序不要弄错了。对于调试信息,可以为空,但不能缺少,否则会报错,常用{}来代替。我们看源代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def _step (self, action) : state = self.state #判断系统当前状态是否为终止状态 if state in self.terminate_states: return state, 0 , True , {} key = "%d_%s" %(state, action) if key in self.t: next_state = self.t[key] else : next_state = state self.state = next_state is_terminal = False if next_state in self.terminate_states: is_terminal = True if key not in self.rewards: r = 0.0 else : r = self.rewards[key] return next_state, r,is_terminal,{}
step()函数就是这么简单。下面我们重点介绍下如何写render()函数。从图1.1机器人找金币的示意图我们可以看到,网格世界是由一些线和圆组成的。因此,我们可以调用rendering中的画图函数来绘制这些图像。
整个图像是一个600*400的窗口,可用如下代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 from gym.envs.classic_control import renderingself.viewer = rendering.Viewer(screen_width, screen_height) def render (self) : self.line1 = rendering.Line((100 ,300 ),(500 ,300 )) self.line2 = rendering.Line((100 , 200 ), (500 , 200 )) self.line3 = rendering.Line((100 , 300 ), (100 , 100 )) self.line4 = rendering.Line((180 , 300 ), (180 , 100 )) self.line5 = rendering.Line((260 , 300 ), (260 , 100 )) self.line6 = rendering.Line((340 , 300 ), (340 , 100 )) self.line7 = rendering.Line((420 , 300 ), (420 , 100 )) self.line8 = rendering.Line((500 , 300 ), (500 , 100 )) self.line9 = rendering.Line((100 , 100 ), (180 , 100 )) self.line10 = rendering.Line((260 , 100 ), (340 , 100 )) self.line11 = rendering.Line((420 , 100 ), (500 , 100 )) self.kulo1 = rendering.make_circle(40 ) self.circletrans = rendering.Transform(translation=(140 ,150 )) self.kulo1.add_attr(self.circletrans) self.kulo1.set_color(0 ,0 ,0 ) self.kulo2 = rendering.make_circle(40 ) self.circletrans = rendering.Transform(translation=(460 , 150 )) self.kulo2.add_attr(self.circletrans) self.kulo2.set_color(0 , 0 , 0 ) self.gold = rendering.make_circle(40 ) self.circletrans = rendering.Transform(translation=(300 , 150 )) self.gold.add_attr(self.circletrans) self.gold.set_color(1 , 0.9 , 0 ) self.robot= rendering.make_circle(30 ) self.robotrans = rendering.Transform() self.robot.add_attr(self.robotrans) self.robot.set_color(0.8 , 0.6 , 0.4 ) self.line1.set_color(0 , 0 , 0 ) self.line2.set_color(0 , 0 , 0 ) self.line3.set_color(0 , 0 , 0 ) self.line4.set_color(0 , 0 , 0 ) self.line5.set_color(0 , 0 , 0 ) self.line6.set_color(0 , 0 , 0 ) self.line7.set_color(0 , 0 , 0 ) self.line8.set_color(0 , 0 , 0 ) self.line9.set_color(0 , 0 , 0 ) self.line10.set_color(0 , 0 , 0 ) self.line11.set_color(0 , 0 , 0 ) self.viewer.add_geom(self.line1) self.viewer.add_geom(self.line2) self.viewer.add_geom(self.line3) self.viewer.add_geom(self.line4) self.viewer.add_geom(self.line5) self.viewer.add_geom(self.line6) self.viewer.add_geom(self.line7) self.viewer.add_geom(self.line8) self.viewer.add_geom(self.line9) self.viewer.add_geom(self.line10) self.viewer.add_geom(self.line11) self.viewer.add_geom(self.kulo1) self.viewer.add_geom(self.kulo2) self.viewer.add_geom(self.gold) self.viewer.add_geom(self.robot) self.x=[140 ,220 ,300 ,380 ,460 ,140 ,300 ,460 ] self.y=[250 ,250 ,250 ,250 ,250 ,150 ,150 ,150 ] if self.state is None : return None self.robotrans.set_translation(self.x[self.state-1 ], self.y[self.state- 1 ]) return self.viewer.render(return_rgb_array=mode == 'rgb_array' )
以上便完成了render()函数的建立
reset()函数常常用随机的方法初始化机器人的状态,即:
1 2 3 def _reset (self) : self.state = self.states[int(random.random() * len(self.states))] return self.state
全部的代码请去github上下载学习。下面重点讲一讲如何将建好的环境进行注册,以便通过gym的标准形式进行调用。其实环境的注册很简单,只需要3步:
第一步:将我们自己的环境文件(我创建的文件名为grid_mdp.py)拷贝到你的gym安装目录/gym/gym/envs/classic_control文件夹中。(拷贝在这个文件夹中因为要使用rendering模块。当然,也有其他办法。该方法不唯一)
第二步:打开该文件夹(第一步中的文件夹)下的__init__.py文件,在文件末尾加入语句:from gym.envs.classic_control.grid_mdp import GridEnv
第三步:进入文件夹你的gym安装目录/gym/gym/envs,打开该文件夹下的__init__.py文件,添加代码:
1 2 3 4 5 6 7 8 register( id='GridWorld-v0' , entry_point='gym.envs.classic_control:GridEnv' , max_episode_steps=200 , reward_threshold=100.0 , )
第一个参数id就是你调用gym.make(‘id’)时的id, 这个id你可以随便选取,我取的,名字是GridWorld-v0
第二个参数就是函数路口了。
后面的参数原则上来说可以不必要写。
经过以上三步,就完成了注册。
下面,我们给个简单的demo来测试下我们的环境的效果吧:
我们依然写个终端程序:
1 2 3 4 5 import gymenv = gym.make('GridWorld-v0' ) env.reset() env.render()