
《漫画机器学习入门》总结
机器学习是指计算机通过不断地处理数据并修正算法和参数来学习各种规则, 从而不断改进模型而得到更优化的算法。书中主要讲解了玻尔兹曼机的机器学习
谁是世界上最美丽的人?
-
****特征量****就是如每一个人的年龄,眼睛大小; 特征向量就是每个人的特征量放到一起,特征向量是表达特征的一个数组
-
误差函数: 在美丽程度这个问题上, 误差函数就是—— 计算“美丽程度”的实际输出与给定的理想输出之间的差值
-
最优化问题: 最小化误差函数,其实是一个求解最优化问题:我们的任务就是要找到没有误差或者误差小到满足要求的最适合的模型。这就要通过调节模型中的参数,使误差函数值尽量小,这就是求解(参数)最优化问题。
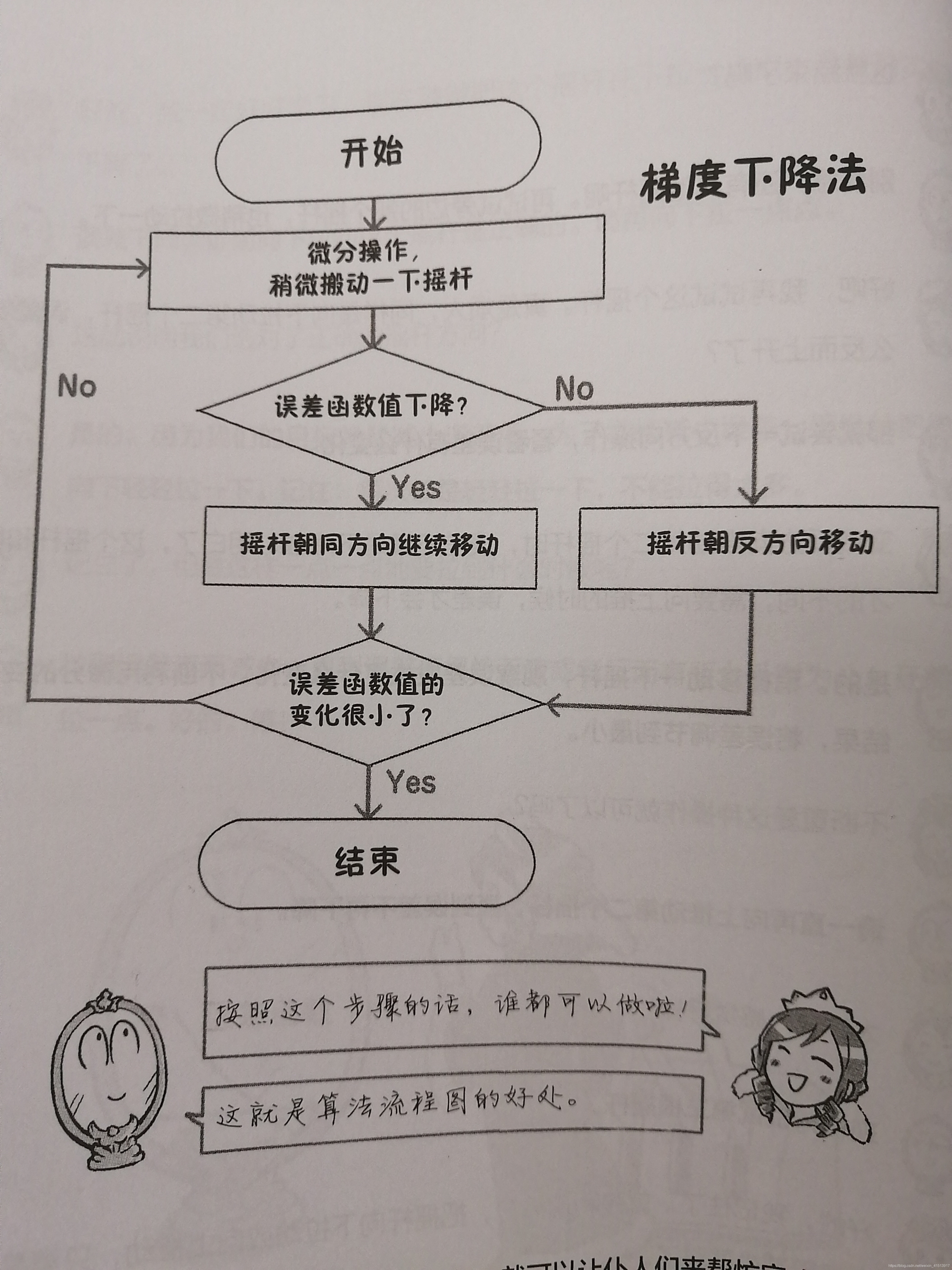
- 微分:稍微拉动一点摇杆,确认误差是否变小。这种操作叫做微分。
- 梯度下降法: 一直拉到误差不再减少,直到误差值保持不变或者反而有所上升时为止。希望不停地调整权重,使得误差一直在朝着减小的方向前进。这种调整误差的方法叫梯度下降法。
-
回归就是:建立模型—拟合—微调
-
机器学习是寻找输入数据与输出数据之间关系(model->function map)的一门学问。
-
每一个特征量都很重要,但是不同特征量的重要程度是不同的,所以需要寻找特征的权重矩阵
-
训练数据和测试数据: 学习和测试是机器学习的两项基本任务。 (1)好的算法很重要; (2)要将获得的数据分为训练用数据和测试用数据;(3)仅仅匹配训练用数据是不行的——仅仅满足训练用数据叫overfit过拟合,如果连训练数据都不符合叫underfit欠拟合
-
验证的方法:交叉验证:将所有的数据分成4组, 每组中1份数据用于测试,3份用于训练
-
复杂化模型——寻找新的特征值:sigmoid 函数:当发现检测的结果不太好,王后想把模型变得更复杂一些。王后尝试将原始的特征量组合起来获得新的特征量,再加权求输出,却发现因为只有乘法和加法的情况这种线性特性,与之前并没有本质区别。因此,引入了sigmoid函数,这个非线性函数。
加权组合,构成新的特征值: 如果我们把将特征量组合,新增加5个特征量的话(如图),摇杆的数量就变成了原来的5倍。
多层神经网络:在单层神经网络的基础上,增加一层非线性变换,结构上也就多了一个中间的曾,就是多层神经网络。
-
只由输入到输出方向进行信息的传递,被称为正向型神经网络; 而双方向都能够进行信息交换的结构被称为双向型神经网络。双向型神经网络典型代表是Hopfield一处的,玻尔兹曼机也是基于这种神经网络。 双向信息处理模式不同于淡出的正向信息处理, 它可以有多个输出结果, 而且从这些输出结果中它可以回忆起以前记忆过的信息,因此也被叫做联想记忆。
-
模型越复杂,网络就越纠缠,拉动一根线就会对整个网络产生较大的影响。反过来,网络中任何一根线又会连接很多其他的线,拉它的时候也会受到很大限制,甚至拉不动。 距离输出层越近的摇杆越容易搬动,这是有梯度的结果。因为搬动一下离输出很近的摇杆,它的效果能够很方便地传递给输出。离输出越远,梯度越难计算,越难调整。===>BP算法, 以及最好不要使用Sigmod函数, 因为容易梯度消失, 可以换用tanh或者reLU(观察函数的微分结果)
-
dropout:为了防止过度学习, 需要掌握平衡, 做出取舍: 适当地选取一定比例的特征量,剩下的全部舍弃不用。
-
批量学习与在线学习:
批量学习(batch learning):将全部数据收集齐了之后一起作为训练用数据使用,这叫做批量学习(batch learning)
在线学习(online learning):与此相对的,随着数据不断地获取而逐步进行的学习则称为在线学习(online learning)
现在批量学习也在改进,有些地方与在线学习差不多, 如使用概率梯度下降法:
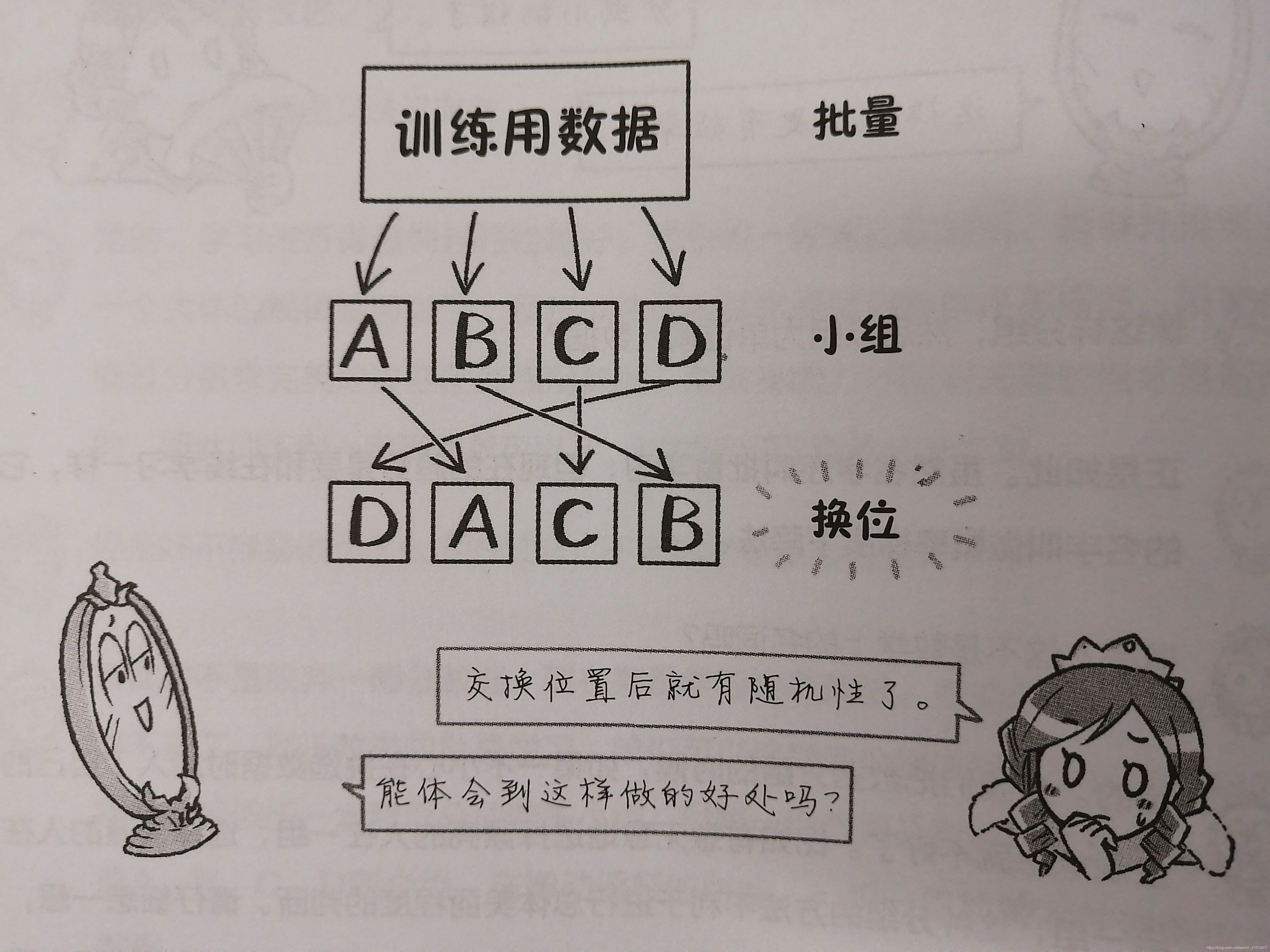
(采用概率的方式去分组,也叫随机选择,就是不能利用某种故意的特定意图去分组)
当利用概率分组后,对每一组数据进行训练,动一下摇杆看误差如何变化,然后再向误差变小的方向搬动摇杆,这就是概率梯度下降法。(通过适当地概率计算,让参数或左或右地跳动着变化)
这种算法考虑的是,与其冲着预先规定好的方向一直走下去,倒不如是不是地左看看,右看看。这样反倒更容易找到隐藏的近路。
在线学习和随机梯度下降法的优势在于, 可以捕捉灵光霎现的机会, 增加了跳脱鞍点的可能性。
粮食问题
-
感知机perceptron(弗兰克·罗森布拉特)和支持向量机SVM(Vladmir N.Vapnik)
感知机:移动分割超平面进行数据分类。感知机的缺点:非线性模型处理不好
支持向量机:使分割超平面处于一种非常“好”的状态,即所有数据点尽量都远离分割超平面,因此能够更好的识别并且使得安全裕量最大
-
矩阵的秩:= 模式的种类, 一个模式以一行向量表示。矩阵中两行的规律相似,应该属于同一种模式。假设数据中存在某些模式,那么在矩阵中一定会存在某一行的数值代表该模式,其他的某一行代表另一种模式。
如果模式能够从可见数据中推演出来,通过对可见数据做有效处理,就能够推测出不可见的那部分数据,这其实是一种无监督学习:希望能够完美地补充矩阵中空白的数据,并能够预测出新的模式。(计算机从大量数据中通过自己的分析来找出规律,叫做无监督学习)
-
预测方面有监督/无监督的不同 :
从数据中学到东西,这一点是一致的。之后,在是否进行预测这一点上是不同的。
有监督学习是希望计算机越来越聪明并逐渐能够代替人的某些工作。
无监督学习,是希望计算机从特征量中选择出我们容易理解的某种模式,将模式分成若干或者某种形式的分类。 -
稀疏化:有些算法会将不重要的特征量的权重直接设定为0,舍弃一些不重要的东西, 导致矩阵中产生很多0, 这种矩阵将稀疏矩阵。
-
非负矩阵分解( Nonnegative Matrix Factor ): 非负,指在计算的时候不使用负值,也就是只做加法运算。就像用钢笔描绘人脸,先有眼睛,鼻子,再加上嘴等等。这些都是一个一个添加的。(非负好比用钢笔作画不能删除, 而普通作画是用铅笔, 所以可以有负值)
如果也用减法,就像用铅笔,还可以用橡皮擦去一些地方。
基于玻尔兹曼机器学习的图像处理方法
首先要明确的一点是, 图片是由像素组成的。每一个像素到底是呈现数模颜色,这是由数据来决定的。
-
玻尔兹曼机器学习:将图像的颜色数据输入到玻尔兹曼机中,计算机通过分析这些数据,就可以得到实际图像的特征,各像素点显示某种颜色的概率,以及相邻像素间的关系。这种过程叫做玻尔兹曼机器学习。
-
似然度: 相似的程度。 机器学习的目的要么是让误差值最小,要么是让似然度最大
-
采样:将实际提供的数据输入到玻尔兹曼机后, 模型会输出伪数据(重构数据), 这个自身不断产生数据的过程就叫做采样 sampling
玻尔兹曼机器学习在进行时,采用马尔科夫蒙特卡罗方法,来逐一考虑相邻像素之间的关系,来完成双向型神经网络的信息流动。这是一种在整个网络结构中的循环,在这一过程中还要不断地采集大量的重构数据。很费时间。==> 替代算法是,单纯考虑由相邻像素传送过来的信息,平均场近似法

-
中间结果包含每一个像素颜色的变化过程,也能够构成中间过程的许多图像。这些中间产生的图像数据就是重构数据, 也可以叫做伪数据。其实核心就是“依据临近像素的数据, 在现有的参数值情况下, 预测中心像素的颜色值”
-
机器学习与统计力学: 我们在研究原子和分子的时候, 位置、运动扽信息是分析研究的对象, 但是统计力学有趣的地方是利用统计学理论去获取事物整体的特征。类比机器学习, 就像我们并不去计较每一个颗粒的位置和速度, 对于机器学习我们也是希望得到大量数据间的整体组合信息, 这种整体组合信息在最优化问题求解时就是推到出函数模型
-
可见变量、隐含变量:在图像中, 每一个像素颜色的数值时可以直接读取的, 这一部分就叫做可见变量。由可见变量之间关联关系构成的新变量称为隐含变量, 从而可以建立出眼睛、鼻子等部件, 从而将利用各个部件就可以将图像分成各个部分了。 利用上述方式就可以以“开关”的形式来操作了,通过像素和开关之间的关系就可以决定在可见变量一侧表示出什么, 这种方法认为可见变量之间没有任何关系, 各个开关之间也没有关联。只考虑开关与像素之间的关系, 叫做受限玻尔兹曼机(RBM), 有较好的特性, 如一定条件下的独立性
-
变分原理:物理学中, 指自然界中静止实物的一个普遍适用的数学定律,也称最小作用原理。比如在确定了物体的起点和终点后, 通过动能和势能之差就能计算出最短路径。
-
对比散度算法:将实际的颜色数据与建立的模型采集到的伪数据进行比较, 我们希望能够从中找到某些有用的东西。
-
深度玻尔兹曼机将图像数据作为输入, 内部作为隐含变量的各种开关来决定到底输出什么图像, 因此为了能够对应不同的图像, 建立数量巨大的复杂的隐含变量时非常必要的——深度玻尔兹曼机的目的时学习图像中隐含的特征, 知道了图像中拥有的特征可以就可以返回来看可见变量中是否有猫和狗了——传统机器学习和深度学习的区别也在于此, 传统机器学习需要自己手动提取特征(特征工程), 而神经网络可以自己提取特征。
-
受限玻尔兹曼机是两层神经网络。包含输入层,隐藏层,输出层
-
预训练: ①运用在无监督学习中, 不告诉model特征有哪些 ②用预训练网络做微调:一般图片分类的神经网络每一类别的图片量级至少在5000-10000左右,如果没有这么多图片,(使用数据增强的方法后也不够),此时就需要用预训练网络了(在几十万张图片训练集上获得较好效果的图片多分类器)。然后用我们现有的图片在这个预训练网络的基础上继续训练, 利用现有的图片继续训练就是为了让网络重新适应现有的图片训练集, 这种适应过程往往比从头训练一个网络更快更好, 这种方法跟迁移学习的思想很像。
-
自我符号化(在无监督学习中具有代表性):吧收到的输入信号原原本本地返回来。

注意, 左右知识结构上的复制,权值是不一样的。这些权值是需要进行调整后才能满足右边的“输入”等于左边输入的。在这个调整权值的过程中,输入数据所隐含的特征就可以被挖掘出来了。>从而使得中间层具有能够反映输入数据中特征的能力。> 中间层的自我符号化训练其实也是提取特征的过程
-
卷积神经网络:
在处理图像时已有已知的神经网络可以利用了——卷积神经网络。
卷积:卷积是利用了,人在看见图像识别图像时并不需要将所有的细小像素全部看清的特征而设计的。卷积就是在某种程度上将临近的像素组合起来形成新的特征量,然后利用卷积结果进行分析
池化:在图片中即使模糊我们也能通过模糊的影像大致判断出—>数据即使有些差异也能够得出同样的结果。因此可以利用卷积将特征进行排序,将相近的特征进行比较并选用其中的最大值或平均值,叫做池化
▲通过卷积和池化操作,神经网络从而可以将图像中的特征量自动地提取出来了。
Author: Mrli
Link: https://nymrli.top/2020/11/28/《漫画机器学习入门》大关真之——读书笔记/
Copyright: All articles in this blog are licensed under CC BY-NC-SA 3.0 unless stating additionally.