在课程设计实验周里总共读了3本书, 《深度学习算法实践》、《深度学习框架PyTorch快速开发与实战》、《PyTorch深度学习入门》。 其中《深度学习算法实践》、《深度学习框架PyTorch快速开发与实战》比较失望,质量比较差;《PyTorch深度学习入门》的代码质量高一点,但需要理论辅助,由于事先看了李宏毅老师的深度学习,因此还算容易入手。
网上关于《深度学习框架PyTorch快速开发与实战》的评价:
作者一共三个,在封面内侧有简单的介绍, 三个作者的简绍里没有“深度学习”相关的内容(请注意书名).单从这本书的作者介绍来说,这几个作者是很不专业的,换言之,这几个人可能未必够资格写这么一本书(就事论事,没有任何不尊重人的意思)
代码质量差到离谱
PyTorch版本问题(这个是技术相关书籍都会遇到的问题,可以接受)
代码不全,照着书上的代码敲下来,会发现莫名其妙就少了一部分
我第一本代码书看的就是这本, 当时觉得还行, 但在看完《PyTorch深度学习入门》后打算也敲下这本书的代码,结果发现给的样例代码很多都跑不过,并且初看时对每个函数的详细介绍现在看来可能是因为没东西写了,内容非常重复。
▲.以后选书还是得看下作者是否相关专业
(1)闵可夫斯基距离( ∑ i = 1 n ∣ x i − y i ∣ p ) 1 / p \left(\sum_{i=1}^{n}\left|x_{i}-y_{i}\right|^{p}\right)^{1 / p} ( ∑ i = 1 n ∣ x i − y i ∣ p ) 1 / p
该距离最常用的p是2和1,前者是欧几里得距离(Euclidean distance),后者是曼哈顿距离(Manhattan distance)。当p趋近于无穷大时,闵可夫斯基距离转化成切比雪夫距离(Chebyshev distance):lim p → ∞ ( ∑ i = 1 n ∣ x i − y i ∣ p ) 1 p = max i = 1 n ∣ x i − y i ∣ \lim _{p \rightarrow \infty}\left(\sum_{i=1}^{n}\left|x_{i}-y_{i}\right| p\right)^{\frac{1}{p}}=\max _{i=1}^{n}\left|x_{i}-y_{i}\right| lim p → ∞ ( ∑ i = 1 n ∣ x i − y i ∣ p ) p 1 = max i = 1 n ∣ x i − y i ∣
(2)马氏距离(Mahalanobis distance)是由印度统计学家马哈拉诺比斯(PC.Mahalanobis)提出的,表示数据的协方差距离。它是一种有效地计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的。),并且是尺度无关的(Scale-invariant),即独立于测量尺度。对于一个均值为u,协方差矩阵为的多变量向量,其马氏距离为(x-u)Z(-1)(xu)。
(3)余弦相似度,又称为余弦相似性。通过计算两个向量的夹角余弦值来评估它们的相似度。cos θ = a ∙ b ∥ a ∥ ∥ b ∥ \cos \theta=\frac{a \bullet b}{\|a\|\|b\|} cos θ = ∥ a ∥ ∥ b ∥ a ∙ b
数据标准化(归一化)处理,是为了消除指标之间的量纲影响,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。标准化就是一种对样本数据在不同维度上进行一个伸缩变化,也就是不改变原始数据的信息(分布)。这样的好处就是在进行特征提取时,忽略掉不同特征之间的一个度量,而保留样本在各个维度上的信息(分布)。
a.Min-Max标准化(Min-Max Normalization)也称为离差标准化,是对原始数据的线性变换,使结果值映射到[0, 1]之间。转换函数如下:X ∗ = X − min max − min X^{*}=\frac{X-\min }{\max -\min } X ∗ = max − min X − min
b.Z-score标准化方法
为了防止过拟合现象,我们加入了正则化项,常用的有 L1范数和 L2范数。
在训练神经网络时,必须评估网络输出的正确性。众所周知,预期上正确的训练输出数据和实际的训练输出是可比拟的。成本函数便是测量实际和训练输出之间的差异。实际和预期输出之间的零成本将意味着训练神经网络成为可能。BGD即Batch Gradient Descent 。在训练中,每一步迭代都使用训练集的所有内容。也就是利用现有参数对训练集中的每一个输入生成一个估计输出,然后跟实际输出比较,统计所有误差,求平均以后得到平均误差,以此来作为更新参数的依据。SGD全名Stochastic Gradient Descent ,即随机梯度下降。即随机抽取一批样本,以此为根据来更新参数。随机梯度下降算法和批量梯度下降的不同点在于其梯度是根据随机选取的训练集样本来决定的,其每次对theta的更新,都是针对单个样本数据,并没有遍历完整的参数。当样本数据很大时,可能到迭代完成,也只不过遍历了样本中的一小部分。因此,其速度较快,但是其每次的优化方向不一定是全局最优的,但最终的结果是在全局最优解的附近。
Momentum Momentum
AdaGrad AdaGrad
RMSProp
入门coding:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import torchimport matplotlib.pyplot as plt%matplotlib inline def Produce_X (x) : x0 = torch.ones( x.numpy().size) X = torch.stack( (x, x0), dim = 1 ) return X x = torch.Tensor([ 1.4 , 5 , 11 , 16 , 21 ]) y = torch.Tensor( [14.4 , 29.6 , 62 , 85.5 , 113.4 ]) X = Produce_X(x) inputs = X targets = y w = torch.rand(2 , requires_grad = True )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 def draw (outputs, loss) : plt.cla() plt.scatter( x.numpy(), y.numpy() ) plt.plot( x.numpy(), outputs.data.numpy(), 'r-' , lw = 5 ) plt.text(0.5 , 0 , 'loss=%s' % (loss.item()), fontdict = { 'size' :20 , 'color' :'red' }) plt.pause(0.05 ) def train (epochs = 1 , lr = 0.01 ) : for ep in range(epochs): outputs = inputs.mv(w) print(outputs.size()) print(targets.shape) loss = (outputs - targets).pow(2 ).sum() loss.backward() w.data = w.data - lr * w.grad w.grad.zero_() return w, loss w, loss = train(1 , lr = 1e-4 ) print("final loss:" , loss.item()) print("weights:" , w.data)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import torchimport matplotlib.pyplot as pltdef Produce_X (x) : x0 = torch.ones(x.numpy().size) X = torch.stack((x,x0),dim=1 ) return X x = torch.linspace(-3 ,3 ,100000 ) X = Produce_X(x) y = x +1.2 *torch.rand(x.size()) w = torch.rand(2 ) plt.scatter(x.numpy(),y.numpy(),s=0.001 ) plt.show()
1 2 3 4 5 6 7 8 9 10 11 CUDA = torch.cuda.is_available() if CUDA: inputs = X.cuda() targets = Y.cuda() w = w.cuda() w.requires_grad = True else : inputs = X targets = Y w = w w.requires_grad = Truue
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def draw (outputs, loss) : if CUDA: outputs = outputs.cpu() plt.cla() plt.scatter( x.numpy(), y.numpy() ) plt.plot( x.numpy(), outputs.data.numpy(), 'r-' , lw = 5 ) plt.text(0.5 , 0 , 'loss=%s' % (loss.item()), fontdict = { 'size' :20 , 'color' :'red' }) plt.pause(0.05 ) def train (epochs = 1 , lr = 0.01 ) : for ep in range(epochs): outputs = inputs.mv(w) loss = (outputs - targets).pow(2 ).sum() loss.backward() w.data = w.data - lr * w.grad w.grad.zero_() return w, loss
1 2 3 4 5 6 7 8 9 from time import perf_counterstart = perf_counter() w, loss = train(1000 , lr = 1e-4 ) finish = perf_counter() t = finish - start print("计算时间:" , t) print("final loss:" , loss.item()) print("w:" , w.data) print(type(loss))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 import torchimport matplotlib.pyplot as pltfrom torch import nn,optimfrom time import perf_counterimport numpy as npfrom typing import Anyx = torch.unsqueeze(torch.linspace(-3 , 3 , 1000 ), dim = 1 ) y = x + 1.2 * torch.rand(x.size()) class LR (nn.Module) : def __init__ (self) : super(LR, self).__init__() self.liner = nn.Linear(1 , 1 ) def forward (self, x: Any) : out = self.liner(x) return out CUDA = torch.cuda.is_available() if CUDA: LR_model = LR().cuda() inputs = x.cuda() target = y.cuda() else : LR_model = LR() inputs = x target = y criterion = nn.MSELoss() optimizer = optim.SGD(LR_model.parameters(), lr=1e-4 ) def draw (output, loss) : if CUDA: output = output.cpu() plt.cla() plt.scatter(x.numpy(), y.numpy(), marker='.' ) plt.plot(x.numpy(), output.data.numpy(), 'r-' , lw=5 ) plt.text(0.5 , 0 , 'Loss=%.8s' % (loss.item()), fontdict={'size' : 20 , 'color' : 'red' }) plt.pause(0.005 ) def train (model, criterion, optimizer, epochs) : for ep in range(epochs): output = model(inputs) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() if ep % 80 == 0 : draw(output, loss) return model, loss start = perf_counter() LR_model,loss = train(LR_model,criterion,optimizer,10000 ) finish = perf_counter() time = finish-start print("计算时间:%s" % time) print("final loss:" ,loss.item()) print("weights:" ,list(LR_model.parameters()))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 import torchimport matplotlib.pyplot as pltfrom torch import nn, optimfrom time import perf_counterimport numpy as npfrom typing import Anydef draw (output, loss) : if CUDA: output = output.cpu() plt.cla() plt.scatter(x.numpy(), y.numpy(), marker='.' ) plt.plot(x.numpy(), output.data.numpy(), 'r-' , lw=5 ) plt.text(-2 , -10 , 'Loss=%.6s' % (loss.item()), fontdict={'size' : 20 , 'color' : 'red' }) plt.pause(0.005 ) x = torch.unsqueeze(torch.linspace(-3 , 3 , 1000 ), dim=1 ) y = x.pow(3 ) + 0.3 * torch.rand(x.size()) plt.scatter(x.numpy(), y.numpy()) plt.show() class Net (nn.Module) : def __init__ (self, input_feature, num_hidden, outpus) : super(Net, self).__init__() self.hidden = nn.Linear(input_feature, num_hidden) self.out = nn.Linear(num_hidden, outpus) def forward (self, x) : x = nn.functional.relu(self.hidden(x)) x = self.out(x) return x CUDA = torch.cuda.is_available() if CUDA: net = Net(input_feature= 1 , num_hidden= 20 , outpus= 1 ).cuda() inputs = x.cuda() target = y.cuda() else : net = Net(input_feature= 1 , num_hidden= 20 , outpus= 1 ) inputs = x target = y criterion = nn.MSELoss() optimizer = optim.SGD(net.parameters(), lr=0.01 ) def train (model, criterion, optimizer, epochs) : for ep in range(epochs): output = model(inputs) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() if ep % 80 == 0 : draw(output, loss) return model, loss net, loss = train(net, criterion, optimizer, 1 ) print(type(loss)) print("final loss:" , loss.item())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 import torchimport matplotlib.pyplot as pltfrom torch import nn, optimfrom time import perf_counterimport numpy as npdef draw (output) : if CUDA: output=output.cpu() plt.cla() output = torch.max((output), 1 )[1 ] pred_y = output.data.numpy().squeeze() target_y = y.numpy() plt.scatter(x.numpy()[:, 0 ], x.numpy()[:, 1 ], c=pred_y, s=10 , lw=0 , cmap='RdYlGn' ) accuracy = sum(pred_y == target_y)/1000.0 plt.text(1.5 , -4 , 'Accuracy=%s' % (accuracy), fontdict={'size' : 20 , 'color' : 'red' }) plt.pause(0.1 ) N = 500 cluster = torch.ones(N, 2 ) data0 = torch.normal(4 * cluster, 2 ) data1 = torch.normal(-4 * cluster, 2 ) label0 = torch.zeros(N) label1 = torch.ones(N) x = torch.cat((data0, data1), ).type(torch.FloatTensor) y = torch.cat((label0, label1), ).type(torch.LongTensor) plt.scatter(x.numpy()[:, 0 ], x.numpy()[:, 1 ], c = y, s=10 , lw=0 , cmap='RdYlGn' ) plt.show() class Net (nn.Module) : def __init__ (self) : super(Net, self).__init__() self.linear = nn.Linear(2 , 2 ) def forward (self, x) : x = self.linear(x) x = torch.sigmoid(x) return x CUDA = torch.cuda.is_available() if CUDA: net = Net().cuda() inputs = x.cuda() targets = y.cuda() else : net = Net() inputs = x targets = y def train (model, criterion, optimizer, epochs) : for ep in range(epochs): outputs = model(inputs) loss = criterion(outputs, targets) optimizer.zero_grad() loss.backward() optimizer.step() if ep % 80 == 0 : draw(outputs) optimizer = optim.SGD(net.parameters(), lr=0.02 ) criterion = nn.CrossEntropyLoss() train(net, criterion, optimizer, 1000 )
torch.randn(5,2)是标准正态分布取(5,2)数
data0 = torch.normal(4 * cluster, 2) , 第一个参数是mean, 第二个是std, 维度根据传入的tensor参数决定
torch.norm() 是求范数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 import torchfrom torch import nn, optimimport torch.nn.functional as Fimport matplotlib.pyplot as pltdef draw (output) : if CUDA: output=output.cpu() plt.cla() output = torch.max((output), 1 )[1 ] pred_y = output.data.numpy().squeeze() target_y = y.numpy() plt.scatter(x.numpy()[:, 0 ], x.numpy()[:, 1 ], c=pred_y, s=10 , lw=0 , cmap='RdYlGn' ) accuracy = sum(pred_y == target_y)/1500.0 plt.text(0.5 , -6 , 'Accuracy=%.6s' % (accuracy), fontdict={'size' : 20 , 'color' : 'red' }) plt.pause(0.1 ) N = 500 cluster = torch.ones(N, 2 ) data0 = torch.normal(4 *cluster, 2 ) data1 = torch.normal(-4 *cluster, 1 ) data2 = torch.normal(-8 *cluster, 1 ) label0 = torch.zeros(N) label1 = torch.ones(N) label2 = label1 * 2 x = torch.cat((data0, data1, data2), ).type(torch.FloatTensor) y = torch.cat((label0, label1, label2), ).type(torch.LongTensor) plt.scatter(x.numpy()[:, 0 ], x.numpy()[:, 1 ], c=y.numpy(), s=10 , lw=0 , cmap='RdYlGn' ) plt.show() class Net (nn.Module) : def __init__ (self, input_feature, num_hidden, outputs) : super(Net, self).__init__() self.hidden = nn.Linear(input_feature, num_hidden) self.out = nn.Linear(num_hidden, outputs) def forward (self, x ) : x = F.relu( self.hidden(x) ) x = F.softmax(self.out(x)) return x CUDA = torch.cuda.is_available() if CUDA: net = Net(input_feature=2 , num_hidden=20 ,outputs=3 ).cuda() inputs = x.cuda() target = y.cuda() else : net = Net(input_feature=2 , num_hidden=20 ,outputs=3 ) inputs = x target = y optimizer = optim.SGD(net.parameters(), lr=0.02 ) criterion = nn.CrossEntropyLoss() def train (model, criterion, optimizer, epochs) : for ep in range(epochs): outputs = model(inputs) loss = criterion(outputs, target) optimizer.zero_grad() loss.backward() optimizer.step() if ep % 80 == 0 : draw(outputs) train(net, criterion, optimizer, 10000 )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 import osimport torchfrom torch import nn, optimimport torch.nn.functional as Ffrom torchvision import datasets, transformstransform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.1307 ,), (0.3081 ,)) ]) trainset = datasets.MNIST('data' , train=True , download=True , transform=transform) testset = datasets.MNIST('data' , train=False , download=True , transform=transform) class LeNet (nn.Module) : def __init__ (self) : super(LeNet, self).__init__() self.c1 = nn.Conv2d(1 , 6 , (5 , 5 )) self.c3 = nn.Conv2d(6 , 16 , 5 ) self.fc1 = nn.Linear(16 * 4 * 4 , 120 ) self.fc2 = nn.Linear(120 , 84 ) self.fc3 = nn.Linear(84 , 10 ) def forward (self, x) : x = F.max_pool2d(F.relu(self.c1(x)), 2 ) x = F.max_pool2d(F.relu(self.c3(x)), 2 ) x = x.view(-1 , self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x def num_flat_features (self, x) : size = x.size()[1 :] num_features = 1 for s in size: num_features *= s return num_features CUDA = torch.cuda.is_available() if CUDA: lenet = LeNet().cuda() else : lenet = LeNet() criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(lenet.parameters(), lr=0.001 , momentum=0.9 ) trainloader = torch.utils.data.DataLoader(trainset, batch_size=4 , shuffle=True , num_workers=0 ) testloader = torch.utils.data.DataLoader(testset, batch_size=4 , shuffle=False , num_workers=0 ) def train (model, criterion, optimizer, epochs=1 ) : for epoch in range(epochs): running_loss = 0.0 for i, data in enumerate(trainloader, 0 ): inputs, labels = data if CUDA: inputs, labels = inputs.cuda(), labels.cuda() optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() running_loss += loss.item() if i % 1000 == 999 : print('[Epoch:%d, Batch:%5d] Loss: %.3f' % (epoch + 1 , i + 1 , running_loss / 1000 )) running_loss = 0.0 print('Finished Training' ) def test (testloader, model) : correct = 0 total = 0 for data in testloader: images, labels = data if CUDA: images = images.cuda() labels = labels.cuda() outputs = model(images) _, predicted = torch.max(outputs.data, 1 ) total += labels.size(0 ) correct += (predicted == labels).sum() print('Accuracy on the test set: %d %%' % (100 * correct / total)) def load_param (model, path) : if os.path.exists(path): model.load_state_dict(torch.load(path)) def save_param (model, path) : torch.save(model.state_dict(), path) load_param(lenet, 'model.pkl' ) train(lenet, criterion, optimizer, epochs=2 ) save_param(lenet, 'model.pkl' ) test(testloader, lenet)
model.eval()是让model变成训练模式, 这主要是因为dropout和batch normalization的操作在训练和测试是不一样的
1 2 3 4 5 6 7 a = torch.Tensor([[1 ,2 ,3 ],[2 ,1 ,3 ]]) print(a.shape, a.size())
1 2 3 4 5 a = torch.linspace(-3 , 3 , 5 ) print(a, a.size()) b = torch.unsqueeze(a, dim = 1 ) print(b, b.size())
之前书上提供的代码需要求grad的时都是把tensor的requires_grad属性手动置为True(requires_grad默认为False的), 而实际上需要求grad的tensor已经被封装成了可以自动求微分的Variable类型(from torch.autograd import Variable)`
1 2 3 4 5 6 7 8 9 10 11 CUDA = torch.cuda.is_available() if CUDA: inputs = X.cuda() targets = Y.cuda() w = w.cuda() w.requires_grad = True else : inputs = X targets = Y w = w w.requires_grad = True
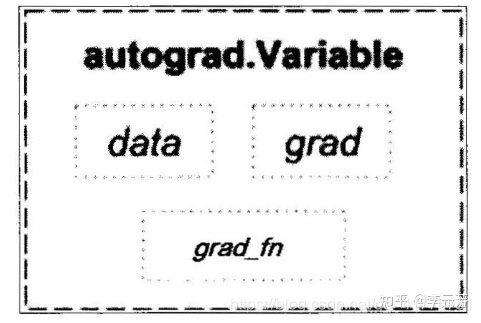
(variable)的理解, pytorch中的变量variable有三个属性,分别是data表示变量中的具体值, grad表示这个变量反向传播的梯度,这个的计算方式下面有专门的一个演示程序, grad_fn表示是通过什么操作得到这个变量的例如( 加减乘除、卷积、反置卷积)
然后定义一个tensor(张量),以及将tensor(张量)转化成variable(变量)。之所以需要将tensor转化成variable是因为pytorch中tensor(张量)只能放在CPU上运算 ,而(variable)变量是可以用GPU进行加速计算的。 所以说这就是为什么pytorch加载图像的时候一般都会使用(variable)变量. 下面一段代码演示的是tensor和variable(变量)之间的转化。
1 2 3 4 5 6 7 8 9 10 11 12 13 x_tensor = torch.ones(3 ) print('张量的类型以及具体值:\n' , type(x_tensor), x_tensor) x_var = Variable(x_tensor, requires_grad = True ) print('变量的类型以及具体的值:\n' , type(x_var), x_var) ''' 张量的类型以及具体值: <class 'torch.Tensor'> tensor([1., 1., 1.]) 变量的类型以及具体的值: <class 'torch.Tensor'> tensor([1., 1., 1.], requires_grad=True) '''
Tensor也可以通过x_tensor.data来获得值,因此比较下来两者的区别就是requires_grad为True、False的关系
摘自: https://blog.csdn.net/qq_41776781/article/details/93967961
这本书应该是我大二见到过最多的书了, 但说实话看完也比较一般, 比较多介绍的是深度学习应用介绍。
这本书感觉也不错,即介绍了torch也介绍了不少pandas和sklearn
本节主要介绍PyTorch的基本概念(如Tensor 和Variable)、自动微分和PyTorch的核心模块。
和其他深度学习框架一样,PyTorch在实现过程中也提出了自己的概念,包括张量,PyTorch中的张量用Tensor表示。初学者可能不知道张量是什么。其实,张量可以简单地理解为一个多维数组,类似于NumPy中的narray对象。
创健张量需要借助tensor提供的Tensor方法或from_numpy方法。理论上可以创建任意维度的多为数组,但最常用的Tensor补超过五维。
除了维度,还可以指定每个维度上的SIZE,如a = torch.Tensor(3, 4, 5, 8),表示创建了一个思维数组,因为Tensor有4个参数,每个参数表示对应维度的大小。因此,变量a可以表示Batch书为3、宽度为4。高度为5,通道数为8的特征图(Feature Map图像卷积运算产生的中间特征)
除了一二维以外,还有三维立方体 :将多个二维矩阵叠加在一起就可以形成三维立方体。三维Tensor 常用于表示图片数据[width,height,channel]。四维多立方体:常见于批量的图片数据,如之前介细的相册就是多张图片的叠加,最常见的形式为[batch, width, height, channel]。五维:表示多个四维tensor相加,常见于视频数据,视频按帧数划分,如50fps(帧/s),表现形式为[frames, batch, width, height, channel]
PyTorch中另外一个和Tensor相关的概念是Variable变量。Variable是对Tensor的封装,是一种特殊的张量,位于torch.autograd自动微分模块中,是为实现自动微分而提出的一种特殊的数据结构。在PyTorch0.4.1之前的版本中,Variable的应用非常广泛 。但是到PyTorch1.0之后,这个数据结构被标注为deprecated ,表示已经过时,并且Variable中的grad和grad_fm等属性也被转移到Tensor中,这个改变进一步精简了接口。由于市面上还存在大量老版本的代码,所以本书也对Variable进行简单介绍。创建Variable需要借助 torch.autograd中提供的Variable方法,它接收Tensor类型的参数。下面通过 Float Tensor 创建 Variable。
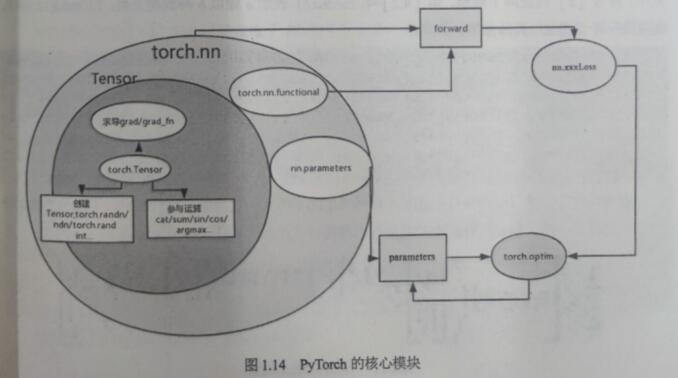
任何好的软件系统必定是经过精心设计和抽象的,PyTorch脱胎于2012年使用La语言编写的To山项目,该项目无论是计算架构设计还是扩展性都是一流的,特别是动态图更是让人耳目一新。torch.nn模块通过functional子模块 提供了大量方法,如conv、ReLU、polling、softmax等。这些方法在网络的forward中调用,结果输出值由torch.nn.xxxLos损失函数计算损失。torch.nn模块 中提供了很多可选的损失函数 ,如MSELoss、CrossEntropyLoss等,将损失传递给优化模块,torch.optim优化模块 提供了大量的优化器,常见的有SGD、Adam等。优化器会根据损失计算并更新梯度,达到优化的目的,最终将更新 parameters。PyTorch的核心模块如图1.14所示。
神经网络核心组件:
层:神经网络的基本结构,将输入张量转换为输出张量
模型:层构成的网络
损失函数:参数学习的目标函数,通过最小化损失函数来学习各种参数
优化器:如何使损失函数最小,这就设计优化器
多个层链接在一起构成一个模型或网络,输入数据通过这个模型转换为预测值,然后损失函数把预测值与真实值进行比较,得到损失值(损失值可以是距离、概率值等),该损失值用于衡量预测值与目标结果的匹配或相似程度,优化器利用损失值更新权重参数,从·而使损失值越来越小。这是一个循环过程,当损失值达到一个阀值或循环次数到达指定次数,循环结束。接下来利用PyTorch的nn工具箱,构建一个神经网络实例。nn中对这些组件都有现成包或类,可以直接使用,非常方便。
利用pytorch内置函数mnist下载数据
利用torchvision对数据进行预处理,调用torch.utils建立一个数据迭代器
可视化源数据
利用nn工具箱构建神经网络模型
实例化模型,并定义损失函数及优化器
训练模型
可视化结果
SGD
SGD带动量optim.SGD(model.parameters(), lr=lr, momentum=momentum)
adagrad
RMSProp(通过修改AdaGrad而来)
Adam(带动量项的RMSProp)
更多见:40 实战 Kaggle 比赛:狗的品种识别(ImageNet Dogs)【动手学深度学习v2】 -引入预训练网络
models
预训练模型,如torchvision.models.resnet34(pretrained=True)
datasets
数据集,如mnist,如datasets.MNIST
对比tensorflow:(X_train, _), (_, _) = mnist.load_data()
ImageFolder,将指定目录下的数据以文件夹为界区分label
注:配合data.DataLoader使用
transforms
数据增强工具,Scale, RandomCrop、RandomResizedCrop, Pad, ColorJitter、RandomHorizontalFlip、ToTensor、CenterCrop
聚合多个变换操作,Compose
utils
data.DataLoader
1 2 3 4 5 6 7 8 9 10 11 12 13 dataloader = torch.utils.data.DataLoader( datasets.MNIST( "../../data/mnist" , train=True , download=True , transform=transforms.Compose( [transforms.Resize(opt.img_size), transforms.ToTensor(), transforms.Normalize([0.5 ], [0.5 ])] ), ), batch_size=opt.batch_size, shuffle=True , )
save_image
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def save_checkpoint (self, folder='checkpoint' , filename='checkpoint.pth.tar' ) : filepath = os.path.join(folder, filename) if not os.path.exists(folder): print("Checkpoint Directory does not exist! Making directory {}" .format(folder)) os.mkdir(folder) else : print("Checkpoint Directory exists! " ) torch.save({ 'state_dict' : self.nnet.state_dict(), }, filepath) def load_checkpoint (self, folder='checkpoint' , filename='checkpoint.pth.tar' ) : filepath = os.path.join(folder, filename) if not os.path.exists(filepath): raise ("No model in path {}" .format(filepath)) map_location = None if args.cuda else 'cpu' checkpoint = torch.load(filepath, map_location=map_location) self.nnet.load_state_dict(checkpoint['state_dict' ]) if j % 10 ==0 and loss < loss_value: torch.save(model, "model.cpkt" ) loss_value = loss
注意点: PIL能show的图片格式不能是tensor,只能是numpy的array,所以需要可视化的话得转换一下。
https://zhuanlan.zhihu.com/p/26893755